
As large language models transition from lab experiments to real-world applications, the way we evaluate their performance must evolve. A casual thumbs-up after scanning a few outputs might be fine for a weekend project, but it doesn’t scale when users depend on models for accuracy, fairness, and reliability.
LLM evaluations or evals do this job for you. They turn subjective impressions into structured, repeatable measurements. More precisely, evals transform the development process from intuition-driven tinkering into evidence-driven engineering, a shift that’s essential if we want LLMs to be more than just impressive demos.
The Eval-Driven Development Cycle: Train, Evaluate, Repeat
At DataNeuron, evaluation (Eval) is the core of our fine-tuning process. We follow a 5-step, iterative loop designed to deliver smarter, domain-aligned models:
1. Raw Docs
The process starts with task definition. Whether you’re building a model for summarization, classification, or content generation, we first collect raw, real-world data, i.e., support tickets, reviews, emails, and chats, directly from your business context.
2. Curated Evals
We build specialized evaluation datasets distinct from the training data. These datasets are crafted to test specific capabilities using diverse prompts, edge cases, and real-world scenarios, ensuring relevance and rigor.
3. LLM Fine-Tune
We fine-tune your model (LLaMA, Mistral, Gemma, etc.) using task-appropriate data and lightweight methods like PEFT or DPO, built for efficiency and performance.
4. Eval Results
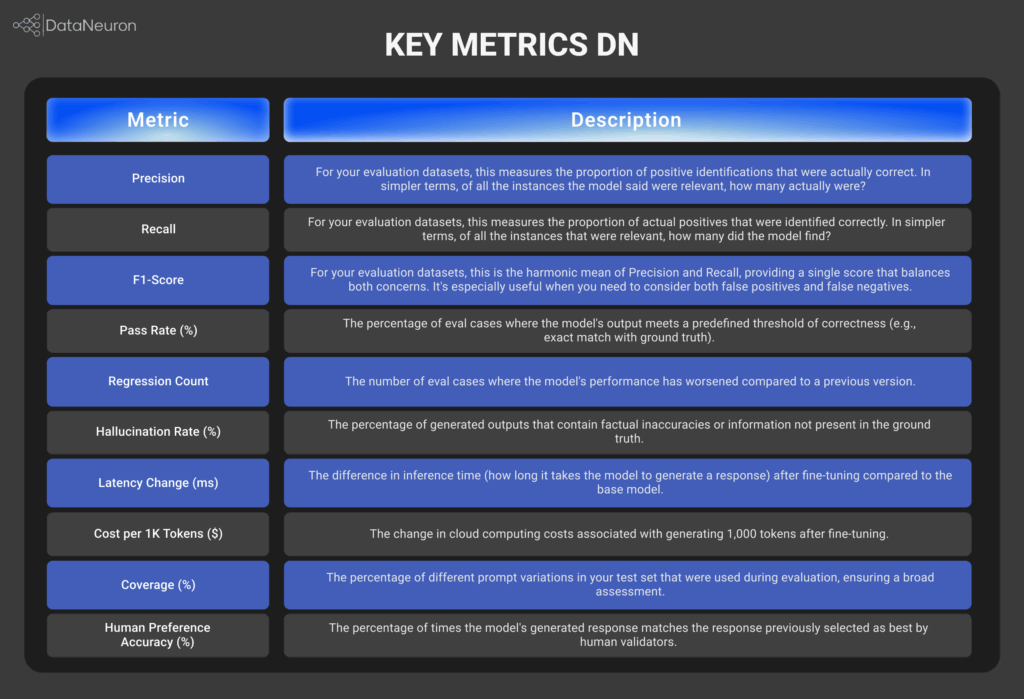
We evaluate your model using curated prompts and subjective metrics like BLEU, ROUGE, and hallucination rate, tracking not just what the model generates, but how well it aligns with intended outcomes.
5. Refinement Loop
Based on eval feedback, we iterate, refining datasets, tweaking parameters, or rethinking the approach. This cycle continues until results meet your performance goals.
Evals guide you towards better models by providing objective feedback at each stage, ensuring a more intelligent and efficient development cycle. So, what exactly goes into a robust LLM evaluation framework?
Core Components of a Robust LLM Evaluation Framework
Human Validation
We recognize the invaluable role of human expertise in establishing accurate benchmarks. Our workflow enables the generation of multiple potential responses for a given prompt. Human validators then meticulously select the response that best aligns with the desired criteria. This human-approved selection serves as the definitive “gold standard” for our evaluations.
Prompt Variations
DataNeuron empowers users to define specific “eval contexts” and create diverse variations of prompts. This capability ensures that your model is rigorously evaluated across a broad spectrum of inputs, thereby thoroughly testing its robustness and generalization capabilities.
Auto Tracking
Our evaluation module automatically compares the responses generated by your fine-tuned model against the human-validated “gold standard.” This automated comparison facilitates the precise calculation of accuracy metrics and allows for the consistent tracking of how well your model aligns with human preferences. The fundamental principle here is that effective fine-tuning should lead the model to progressively generate responses that closely match those previously selected by human validators.
Configurable Pipelines
We prioritize flexibility and control. DataNeuron’s entire evaluation process is highly configurable, providing you with comprehensive command over every stage from data preprocessing and prompt generation to the selection of specific evaluation metrics.
DataNeuron: Your Partner in Eval-Driven Fine-Tuning
At DataNeuron, we’re building a comprehensive ecosystem to streamline your LLM journey, and Evals are a central piece of that puzzle. While we’re constantly evolving, here’s a glimpse of how DataNeuron empowers you with eval-driven fine-tuning:
Core Tenets of DataNeuron’s Evaluation Methodology
Human Validation:
We recognize the invaluable role of human expertise in establishing accurate benchmarks. Our workflow enables the generation of multiple potential responses for a given prompt. Human validators then meticulously select the response that best aligns with the desired criteria. This human-approved selection serves as the definitive “gold standard” for our evaluations.
Prompt Variations:
DataNeuron empowers users to define specific “eval contexts” and create diverse variations of prompts. This capability ensures that your model is rigorously evaluated across a broad spectrum of inputs, thereby thoroughly testing its robustness and generalization capabilities.
Auto Tracking:
Our evaluation module automatically compares the responses generated by your fine-tuned model against the human-validated “gold standard.” This automated comparison facilitates the precise calculation of accuracy metrics and allows for the consistent tracking of how well your model aligns with human preferences. The fundamental principle here is that effective fine-tuning should lead the model to progressively generate responses that closely match those previously selected by human validators.
Configurable Pipelines:
We prioritize flexibility and control. DataNeuron’s entire evaluation process is highly configurable, providing you with comprehensive command over every stage from data preprocessing and prompt generation to the selection of specific evaluation metrics.
Best Practices & Avoiding the Potholes
Here are some hard-earned lessons to keep in mind when implementing eval-driven fine-tuning:
Don’t Overfit to the Eval:
Just like you can overfit your model to the training data, you can also overfit to your evaluation set. To avoid this, diversify your evaluation metrics and periodically refresh your test sets with new, unseen data.
Beware of Eval Drift:
The real-world data your model encounters can change over time. Ensure your evaluation datasets remain representative of this evolving reality by periodically updating them.
Balance Latency and Quality:
Fine-tuning can sometimes impact the inference speed of your model. Carefully consider the trade-off between improved quality and potential increases in latency, especially if your application has strict performance SLAs.
With its focus on structured workflows and integration, DataNeuron urges users to build more reliable and effective LLM-powered applications. Moving beyond subjective assessments is crucial for unlocking the full potential of LLM fine-tuning. Evals provide the objective, data-driven insights you need to build high-performing, reliable models.
At DataNeuron, we’re committed to making this process seamless and accessible, empowering you to fine-tune your LLMs and achieve remarkable results confidently.