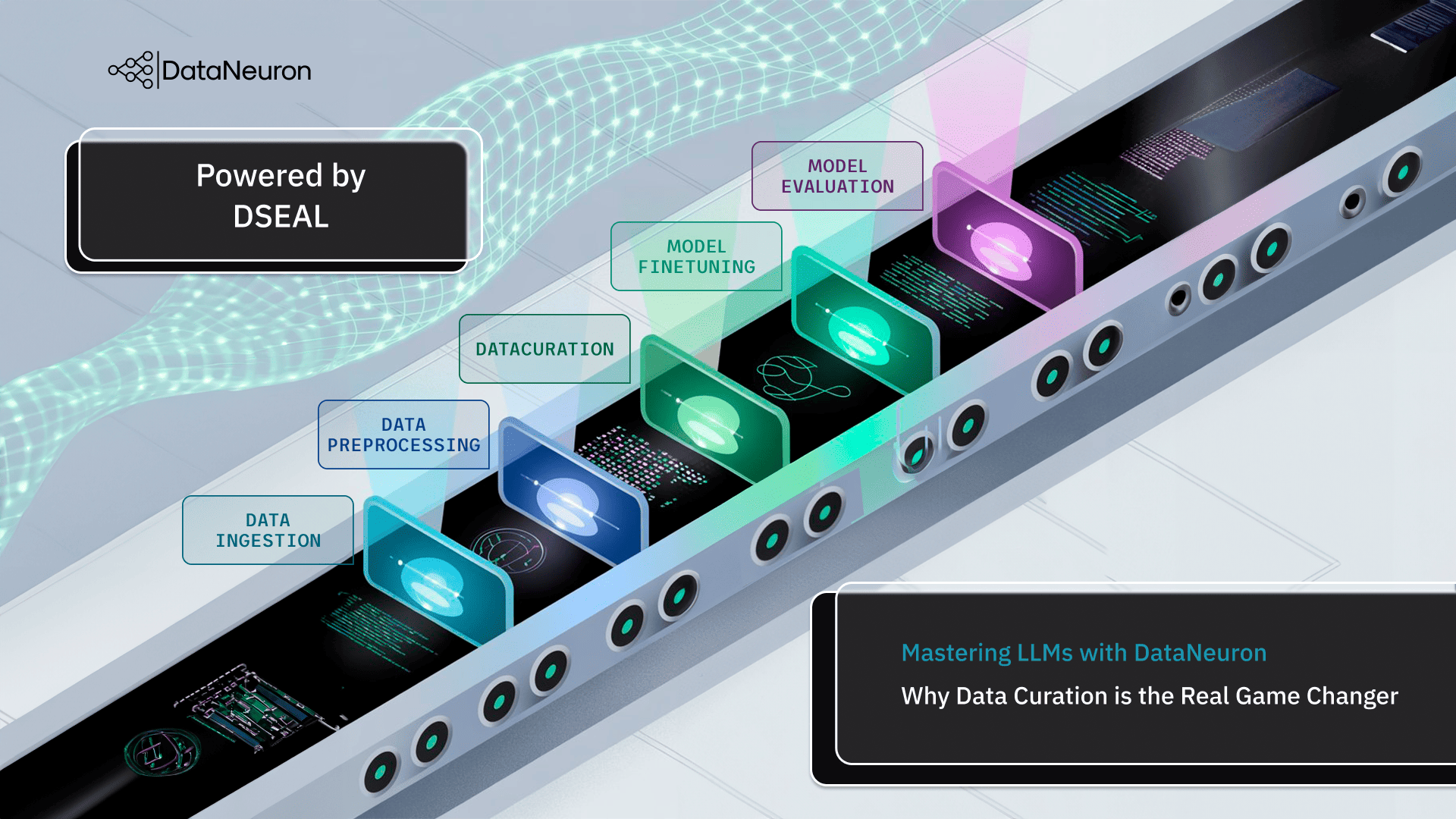
Large Language Models (LLMs) like Llama and Mistral offer immense potential, but their massive size creates deployment challenges, as slow speeds and hefty operational costs hinder their real-world applications. When building a real-time application for your enterprise or aiming for budget deployment at scale, running a 13 B+ parameter model is impractical.
This is where model distillation comes into play.
Think of it as extracting the core wisdom of a highly knowledgeable “teacher” model and transferring it to a smaller, more agile “student” model. At DataNeuron, we’re revolutionizing this process with our LLM Studio. Our platform boasts a smooth workflow that integrates intelligent data curation with a powerful distillation engine that delivers:
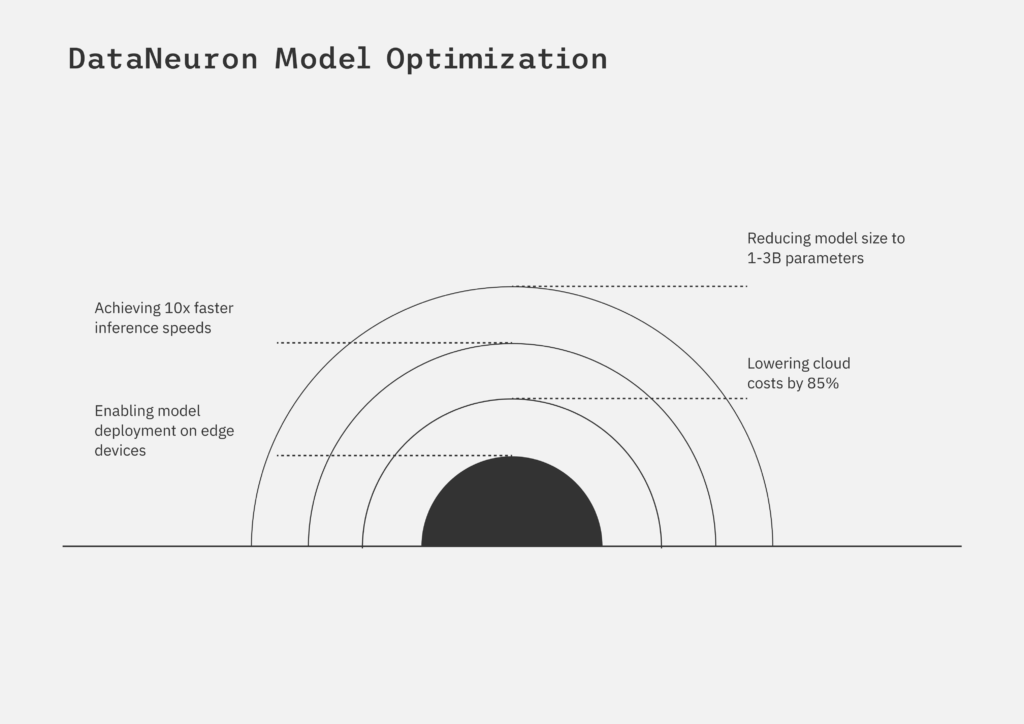
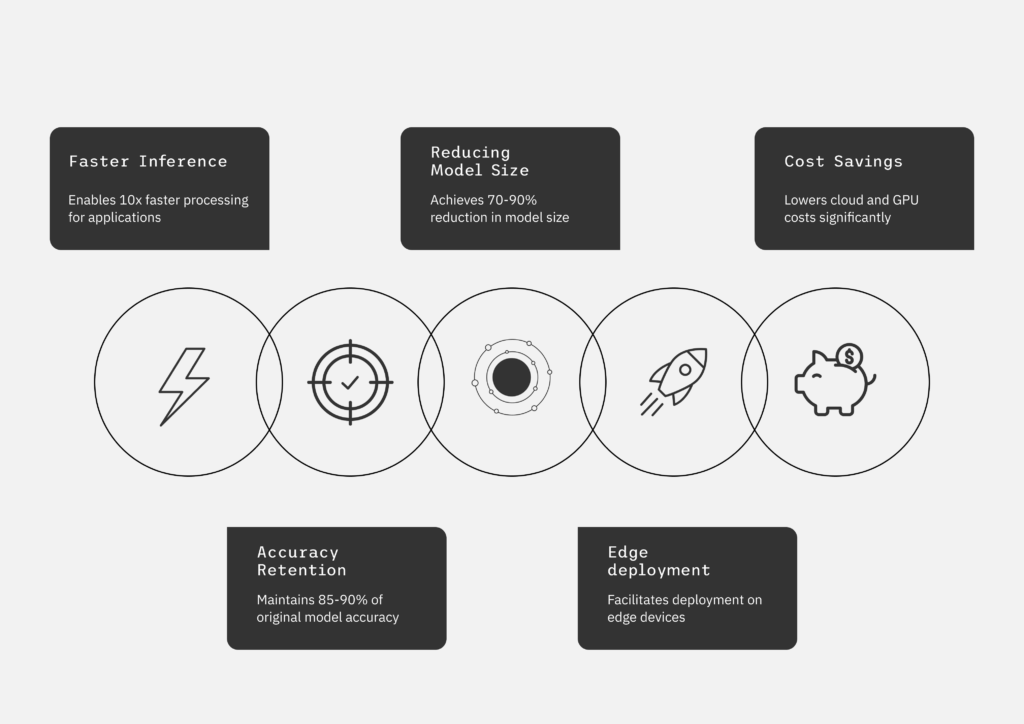
- Up to 10X faster inference speed*
- 90% reduction in model size*
- Significant cost
- Saving on GPU infrastructure
- High accuracy retention
Why is Distillation a Game Changer?
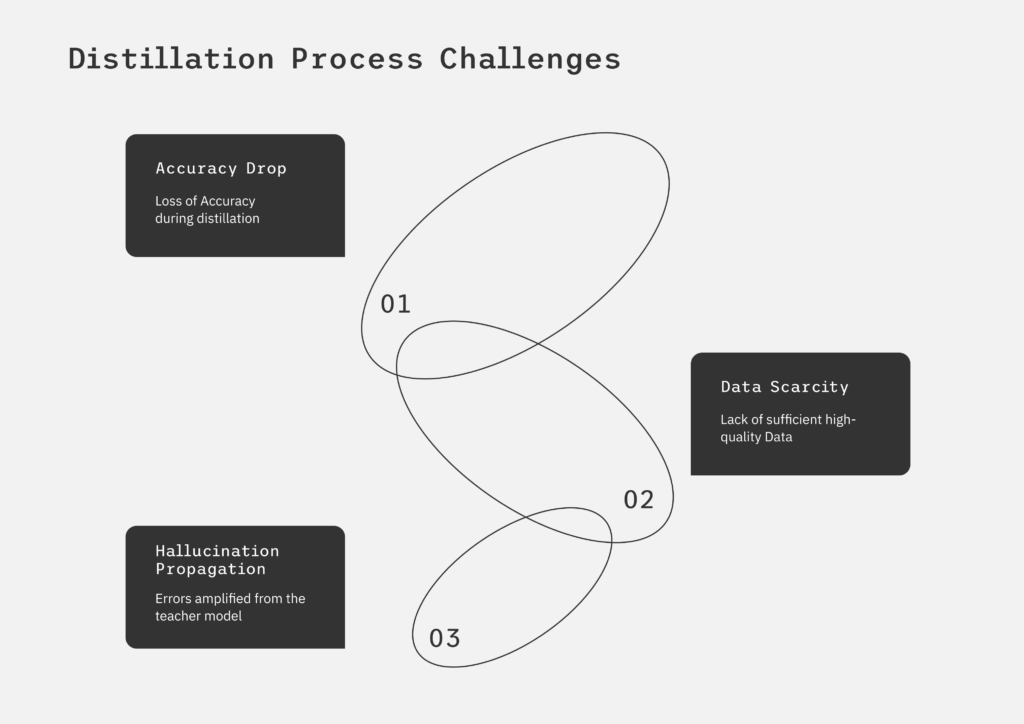
Deploying billion-parameter LLMs to production introduces four major bottlenecks:
- Latency: A few seconds of latency to produce responses from big models is not suitable for real-time use in conversational AI, customer, and real-time interactions
- Infrastructure Cost: LLMs are GPU-intensive. Executing one inference on a +13B model doesn’t sound like much until you are dealing with thousands of simultaneous users. Your cloud expenses surge quickly. A 13B parameter model might end up costing 5X more to execute than a distilled 2B version.
- Infrastructure Demand: Scaling mass models necessitates more powerful GPUs, scaled serving infrastructure, and continuous performance tuning. Deployment on devices becomes infeasible when model sizes exceed 5B parameters.
- Hallucinations: Larger models are more likely to produce inapt or irrelevant answers without proper tuning.
Model distillation removes these limitations by transferring the “knowledge” from a large (teacher) model (e.g., Llama 13B) to a smaller (student) model (e.g., a Llama 1B), retaining performance but vastly improving efficiency.
Navigating the Pitfalls of Traditional Distillation
Traditional model distillation trains a smaller “student” model to mimic a larger “teacher” by matching their outputs. While conceptually simple, valuable distillation is complex, involving careful data selection, proper loss functions (typically based on the teacher’s probability distributions for richer information transfer), and iterative testing with hyperparameters. For example, distilling a large language model for mobile deployment involves training a smaller model on relevant text, possibly incorporating the teacher’s predicted word probabilities to capture style variations.
Without the right tools and technology to manage this complexity, the process can be time-consuming, error-prone, and difficult to scale, limiting the practical implementation of this efficiency-boosting technique.
How is DataNeuron Doing Things Differently?
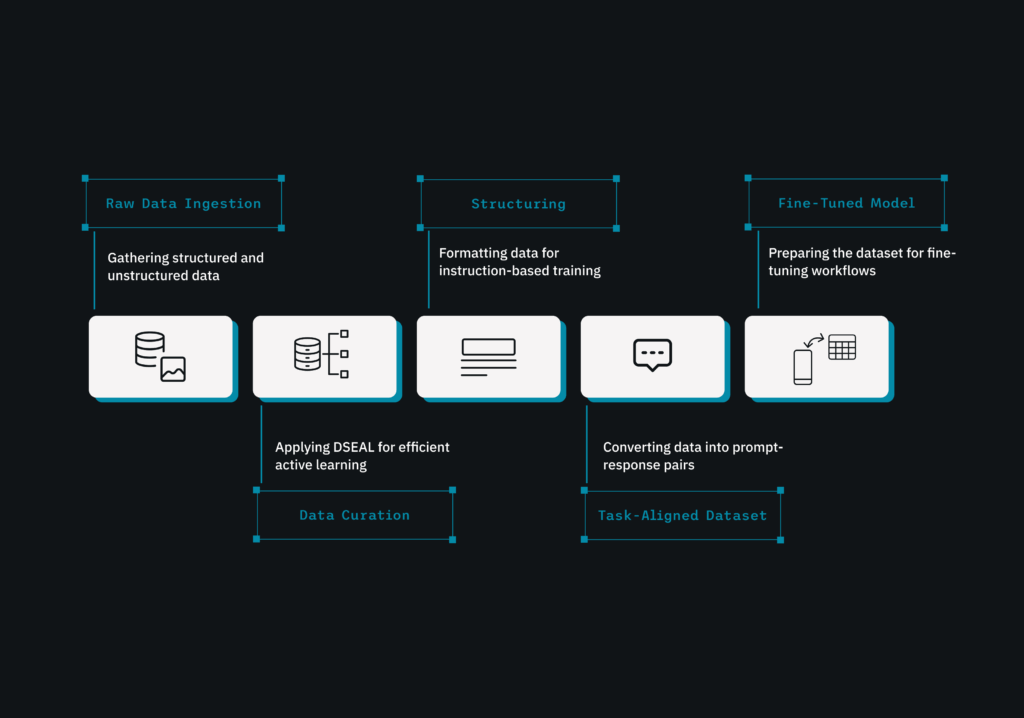
LLM Studio allows you to easily design and manage lightweight, powerful models as per your needs. Our approach promotes intelligent data curation as the foundation for successful information transfer.
Here’s how we streamline the process:
1. Data Selection with Divisive Sampling (D-SEAL)
We deploy our proprietary Divisive Sampling (D-SEAL) system to choose the most informative training data. D-SEAL groups comparable data points, ensuring that your student model learns from a diverse range of examples relevant to its target domain. This curated dataset, potentially built using prompts and responses generated by Retrieval-Augmented Generation (RAG), serves as the bedrock for effective distillation.
For a detailed read, head to the NLP article on D-SEAL
2. Intuitive Model Selection
Our platform features a user-friendly interface for knowledge distillation. You can easily select the Teacher Model available on the DataNeuron platform, such as a suitable high-performing model like Llama 2 70 B.
For the Student Model, you have flexible parameter options to tailor the distilled output to your deployment requirements. Choose from the DataNeuron provided options such as Llama 2 1B, Llama 2 3B, or Llama 2 13B parameters, balancing model size, computational cost, and performance. These options allow you to optimize for various deployment environments.
3. Distillation Engine
The heart of LLM Studio is our powerful distillation engine, which transfers knowledge from the selected teacher model to the smaller student model. The platform handles the underlying complications, allowing you to focus on your desired outcome.
4. Inference & Deployment
Once the distillation process is complete, LLM Studio allows for rapid lean model testing, evaluation, and deployment. You can easily export them for on-device use, integrate them using an API, or deploy them within your cloud infrastructure.
DataNeuron: Beyond Just Smaller Model
At DataNeuron, distillation does more than just shrinking the model size; we create smarter, cost-efficient, and universally deployable AI solutions.
Real-World Impact: Distillation In Action
Internal Search & RAG on a Budget
Such distilled models can still be used to power an internal search capable of domain-specific answering, effectively implemented on a modest cloud setting.
Why Distillation Is The Future of Scalable AI
As foundation models grow in size, competence, and cost, businesses must address the main challenge of scaling their AI applications economically. Model distillation provides an attractive and accessible way ahead.
With DataNeuron LLM Studio, that path is no longer just for field experts and infrastructure engineers. Whether you’re working on mobile apps, internal tools, or public NLP-facing products, training, distilling, and deploying LLMs is simple when you’re associated with us. Smarter models. Smaller footprints. All made easy by DataNeuron.
Ready to see it in action? Book a demo or go through our product walkthrough.