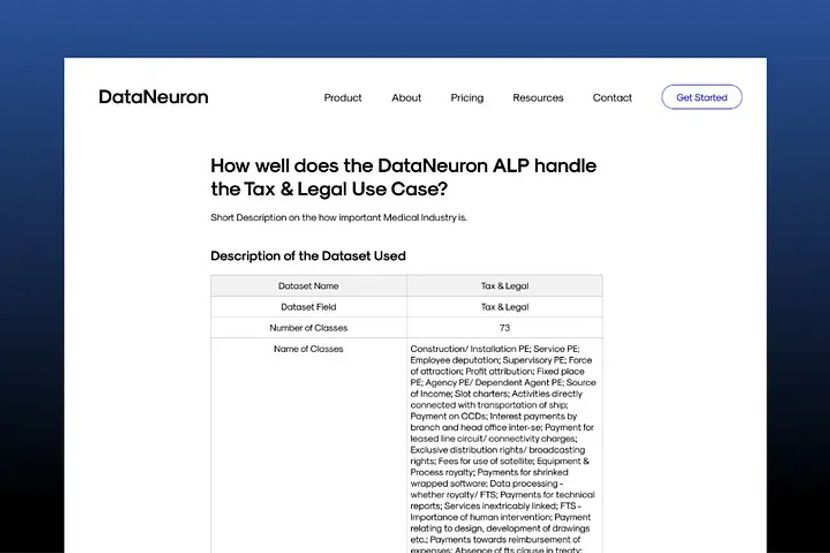
This is the table that explains the dataset that was used to conduct this case study.
Explaining the DataNeuron Pipeline
This is the DataNeuron Pipeline. Ingest, Structure, Validate, Train, Predict, Deploy and Iterate.
Results of our Experiment
Results of our Experiment
Reduction in SME Labelling Effort
During an in-house project, the SMEs have to go through all the paragraphs present in the dataset in order to figure out which paragraphs actually belong to the 73 classes mentioned above. This would usually take a tremendous amount of time and effort.
When using DataNeuron ALP, the algorithm was able to perform strategic annotation on 15000 raw paragraphs and filter out the paragraphs that belonged to the 73 classes and provide 4303 paragraphs to the user for validation. Taking as little as 45 seconds to annotate each paragraph, an in-house project would take an estimate of 187.5 hours just to annotate all the paragraphs while by using DataNeuron, it only took 35.85 hours.
Difference in paragraphs annotated between an in-house solution and DataNeuron.
Advantage of Suggestion-Based Annotation
Instead of making users go through the entire dataset to label paragraphs that belong to a certain class, DataNeuron uses a validation-based approach to make the model training process considerably easier. The platform provides the users with a list of annotated/ labelled paragraphs that are most likely to belong to the same class by using context-based filtering and analysing the masterlist. The users simply have to validate whether the system labelled paragraph belongs to the class mentioned. This validation-based approach also reduces the time it takes to annotate each paragraph. Based on our estimate, it takes approximately 30 seconds for a user to identify whether a paragraph belongs to a particular class. Based on this, it would take an estimate of 35.85 hours for the users to validate 4303 paragraphs provided by the DataNeuron ALP. When compared to the 187.5 hours it would take for an in-house team to complete the annotation process, DataNeuron offers a staggering 81% reduction in time spent.
Difference in time spent annotating between an in-house solution and DataNeuron.
The Accuracy Achieved
When conducting this case study, the accuracy we achieved for the model trained by the DataNeuron ALP was 87% which, considering the high number of classes and small number of training paragraphs, proves to work very well in real world scenarios. The accuracy of the model trained by the DataNeuron ALP can be improved by validating more paragraphs or by adding seed paragraphs.
Calculating the Cost ROI
The number of paragraphs that needs to be annotated in an in-house project is 15000 and it would cost approximately $3280. The number of paragraphs that needs to be annotated when using the DataNeuron ALP is 4303 since most of the paragraphs which did not belong to any of 73 classes were discarded using context-based filtering. The cost for annotating 4303 paragraphs using the DataNeuron ALP is $976.85.
Difference in cost between an in-house solution and DataNeuron.
No Requirement for a Data Science/Machine Learning Expert
The DataNeuron ALP is designed in such a way that no prerequisite knowledge of data science or machine learning is required to utilize the platform to its maximum potential.
For some very specific use cases, a Subject Matter Expert might be required but for the majority of use cases, an SME is not required in the DataNeuron Pipeline.
DataNeuron is thrilled to announce the official launch of the DataNeuron Automated Learning Platform (ALP). The ALP has been strategically designed to accelerate and automate human-in-loop annotation for developing AI solutions. Powered by a data-centric platform, we automate data labeling, the creation of models, and end-to-end lifecycle management of ML.
We are a team of Data Science enthusiasts having first-hand experience of dealing with data analysts, subject matter experts and data scientists to fulfil the labelled data requirements for building highly accurate contextual algorithms for various use-cases. Our aim is to accelerate the development and provide better explainability of AI.
We are also excited to partner with leading venture capitalists, angel investors and strategic advisors in expanding the horizons of DataNeuron.
But why should we switch from human labelling to the DataNeuron ALP? That’s a great question! Based on our findings from the case studies we have conducted, we have found out that using the DataNeuron ALP can reduce the time spent in annotating by a staggering 89.10%, reduce the number of paragraphs validated by 83.55%, reduce the cost expenditure by 77.83% and yield an ROI of an astounding 372.22%.
The DataNeuron Pipeline
Those numbers sound promising but what more can we do on the DataNeuron ALP? Once Again, that’s a great question! Apart from getting accurately labelled data, the DataNeuron ALP can be used to perform no-code prediction. With just a click of a button, the platform can be used to make a prediction on any new paragraphs in exchange for a very minimal fee. This does not require any knowledge of programming and users can utilize this service for any input data from the platform. This can also be integrated into other platforms by making use of the exposed prediction API or the deployed Python package.
As a cherry on top, the DataNeuron ALP is designed in such a way that no prerequisite knowledge of data science or machine learning is required to utilize the platform to its maximum potential. The users only need some knowledge of the domain they are working on and the details of the project and they’re good to go! For some very specific use cases, a Subject Matter Expert might be required but for the majority of use cases, an SME is not required in the DataNeuron Pipeline.
Large Language Models (LLMs) like Llama and Mistral offer immense potential, but their massive size creates deployment challenges, as slowspeeds and heftyoperationalcosts hinder their real-world applications. When building a real-time application for your enterprise or aiming for budget deployment at scale, running a 13 B+ parameter model is impractical.
This is where model distillation comes into play.
Think of it as extracting the core wisdom of a highly knowledgeable “teacher” model and transferring it to a smaller, more agile “student” model. At DataNeuron, we’re revolutionizing this process with our LLM Studio. Our platform boasts a smooth workflow that integrates intelligent data curation with a powerful distillation engine that delivers:
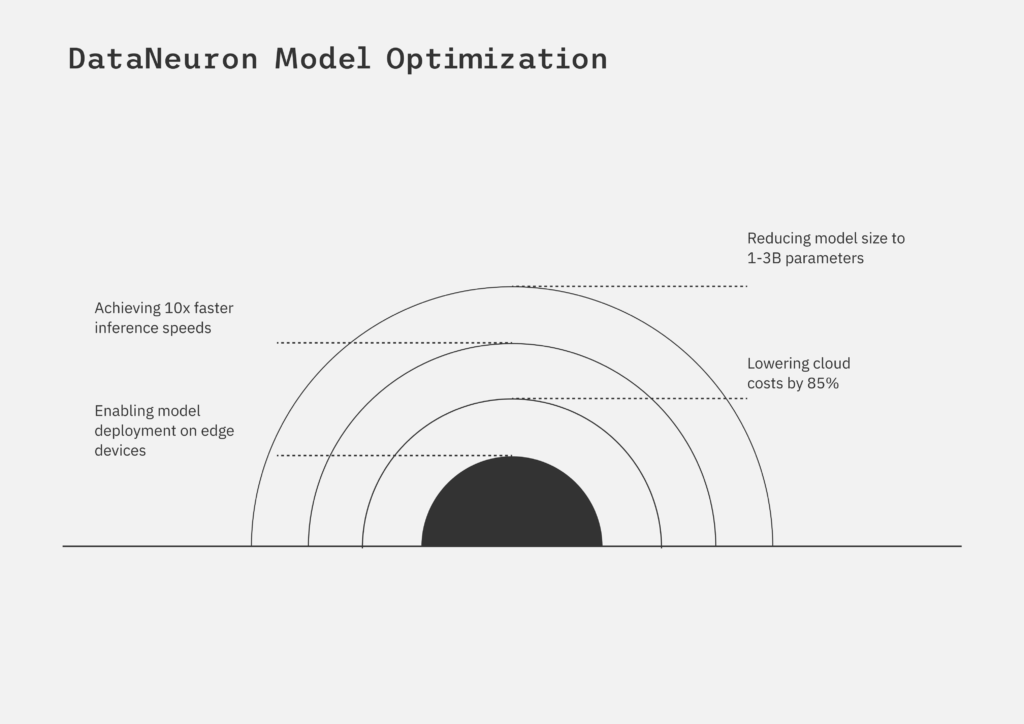
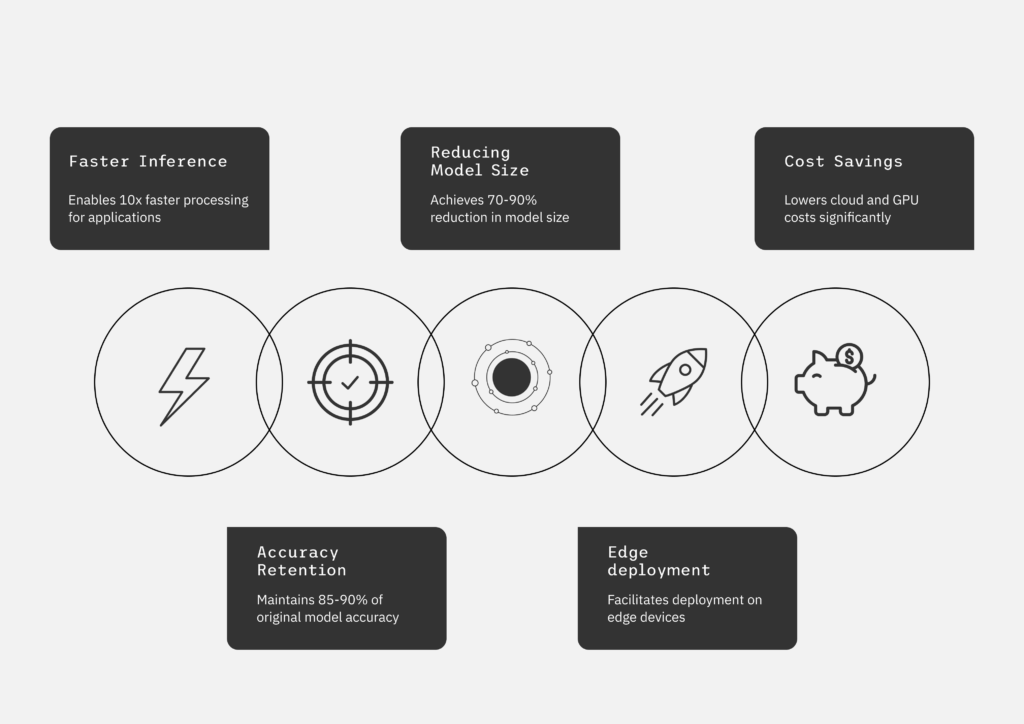
Up to 10X faster inference speed*
90% reduction in model size*
Significant cost
Saving on GPU infrastructure
High accuracy retention
Why is Distillation a Game Changer?
Deploying billion-parameter LLMs to production introduces four major bottlenecks:
Latency: A few seconds of latency to produce responses from big models is not suitable for real-time use in conversational AI, customer, and real-time interactions
Infrastructure Cost: LLMs are GPU-intensive. Executing one inference on a +13B model doesn’t sound like much until you are dealing with thousands of simultaneous users. Your cloud expenses surge quickly. A 13B parameter model might end up costing 5X more to execute than a distilled 2B version.
Infrastructure Demand: Scaling mass models necessitates more powerful GPUs, scaled serving infrastructure, and continuous performance tuning. Deployment on devices becomes infeasible when model sizes exceed 5B parameters.
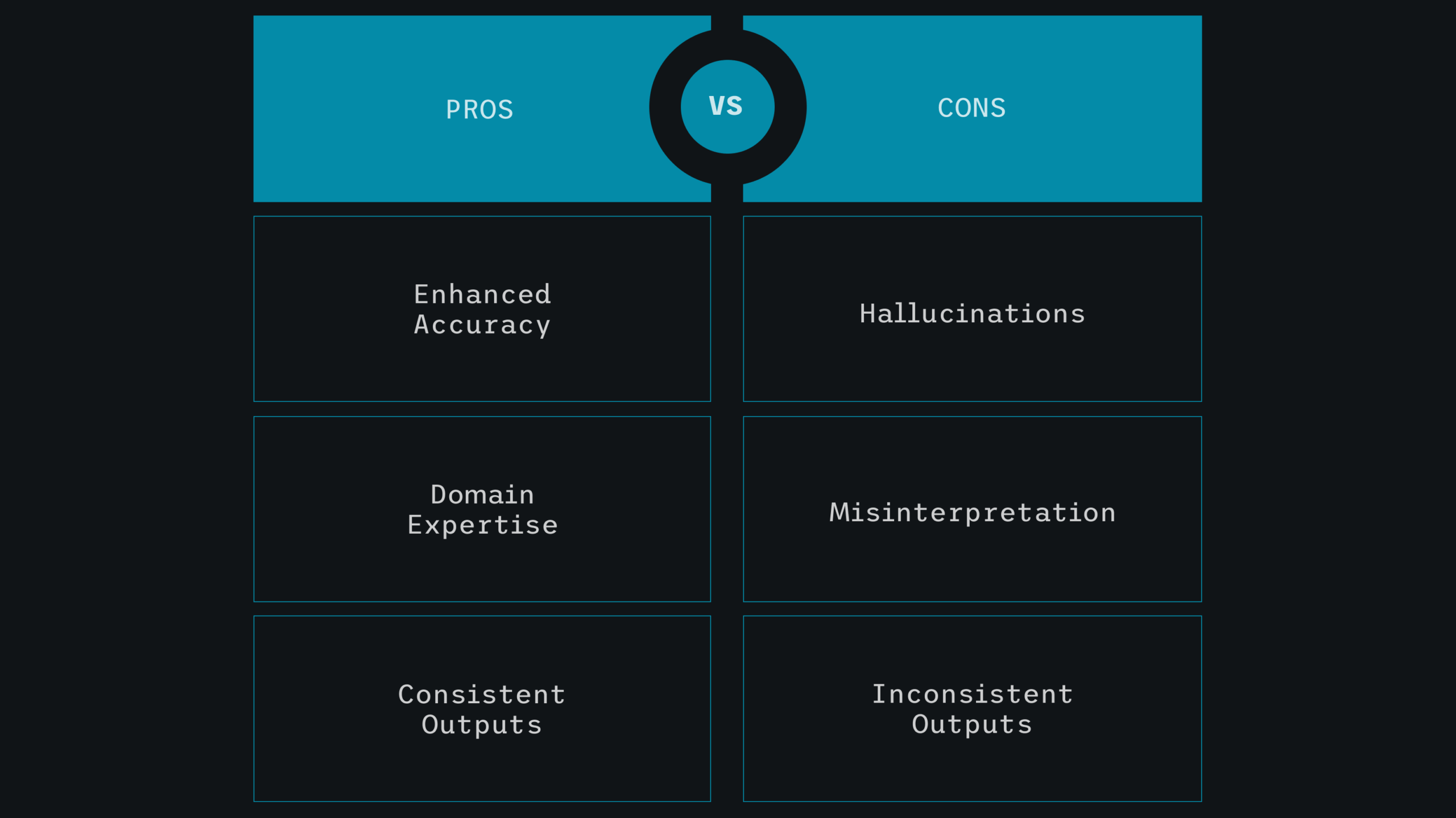
Hallucinations: Larger models are more likely to produce inapt or irrelevant answers without proper tuning.
Model distillation removes these limitations by transferring the “knowledge” from a large (teacher) model (e.g., Llama 13B) to a smaller (student) model (e.g., a Llama 1B), retaining performance but vastly improving efficiency.
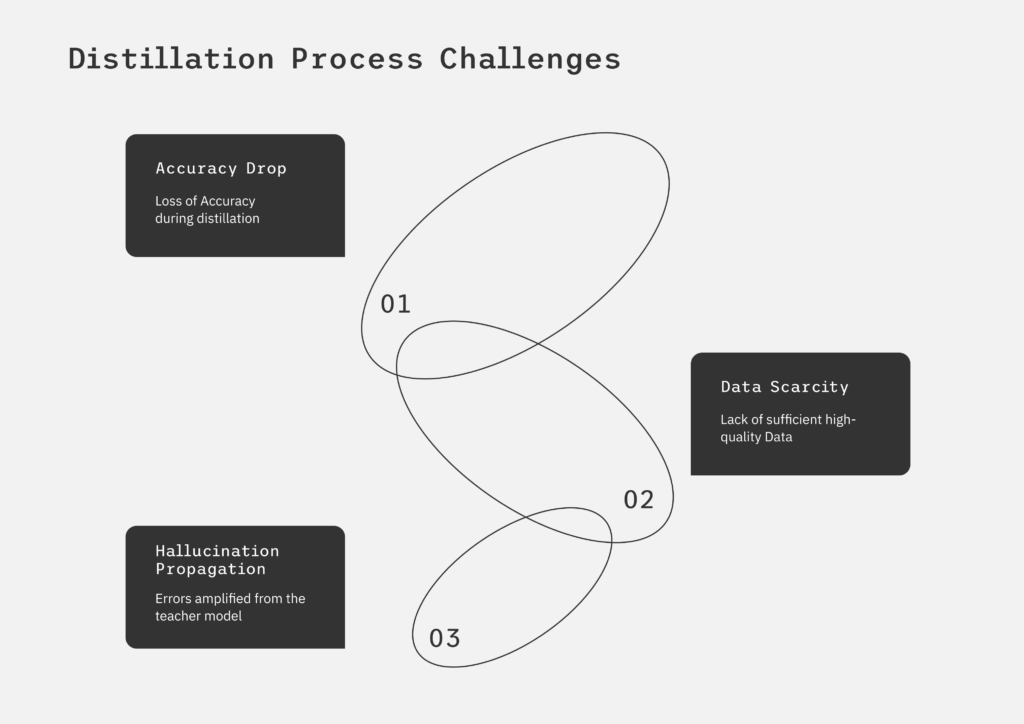
Navigating the Pitfalls of Traditional Distillation
Traditional model distillation trains a smaller “student” model to mimic a larger “teacher” by matching their outputs. While conceptually simple, valuable distillation is complex, involving careful data selection, proper loss functions (typically based on the teacher’s probability distributions for richer information transfer), and iterative testing with hyperparameters. For example, distilling a large language model for mobile deployment involves training a smaller model on relevant text, possibly incorporating the teacher’s predicted word probabilities to capture style variations.
Without the right tools and technology to manage this complexity, the process can be time-consuming, error-prone, and difficult to scale, limiting the practical implementation of this efficiency-boosting technique.
How is DataNeuron Doing Things Differently?
LLM Studio allows you to easily design and manage lightweight, powerful models as per your needs. Our approach promotes intelligent data curation as the foundation for successful information transfer.
Here’s how we streamline the process:
1. Data Selection with Divisive Sampling (D-SEAL)
We deploy our proprietary Divisive Sampling (D-SEAL) system to choose the most informative training data. D-SEAL groups comparable data points, ensuring that your student model learns from a diverse range of examples relevant to its target domain. This curated dataset, potentially built using prompts and responses generated by Retrieval-Augmented Generation (RAG), serves as the bedrock for effective distillation.
Our platform features a user-friendly interface for knowledge distillation. You can easily select the Teacher Model available on the DataNeuron platform, such as a suitable high-performing model like Llama 2 70 B.
For the Student Model, you have flexible parameter options to tailor the distilled output to your deployment requirements. Choose from the DataNeuron provided options such as Llama 2 1B, Llama 2 3B, or Llama 2 13B parameters, balancing model size, computational cost, and performance. These options allow you to optimize for various deployment environments.
3. Distillation Engine
The heart of LLM Studio is our powerful distillation engine, which transfers knowledge from the selected teacher model to the smaller student model. The platform handles the underlying complications, allowing you to focus on your desired outcome.
4. Inference & Deployment
Once the distillation process is complete, LLM Studio allows for rapid lean model testing, evaluation, and deployment. You can easily export them for on-device use, integrate them using an API, or deploy them within your cloud infrastructure.
DataNeuron: Beyond Just Smaller Model
At DataNeuron, distillation does more than just shrinking the model size; we create smarter, cost-efficient, and universally deployable AI solutions.
Real-World Impact: Distillation In Action
Internal Search & RAG on a Budget
Such distilled models can still be used to power an internal search capable of domain-specific answering, effectively implemented on a modest cloud setting.
Why Distillation Is The Future of Scalable AI
As foundation models grow in size, competence, and cost, businesses must address the main challenge of scaling their AI applications economically. Model distillation provides an attractive and accessible way ahead.
With DataNeuron LLM Studio, that path is no longer just for field experts and infrastructure engineers. Whether you’re working on mobile apps, internal tools, or public NLP-facing products, training, distilling, and deploying LLMs is simple when you’re associated with us. Smarter models. Smaller footprints. All made easy by DataNeuron.
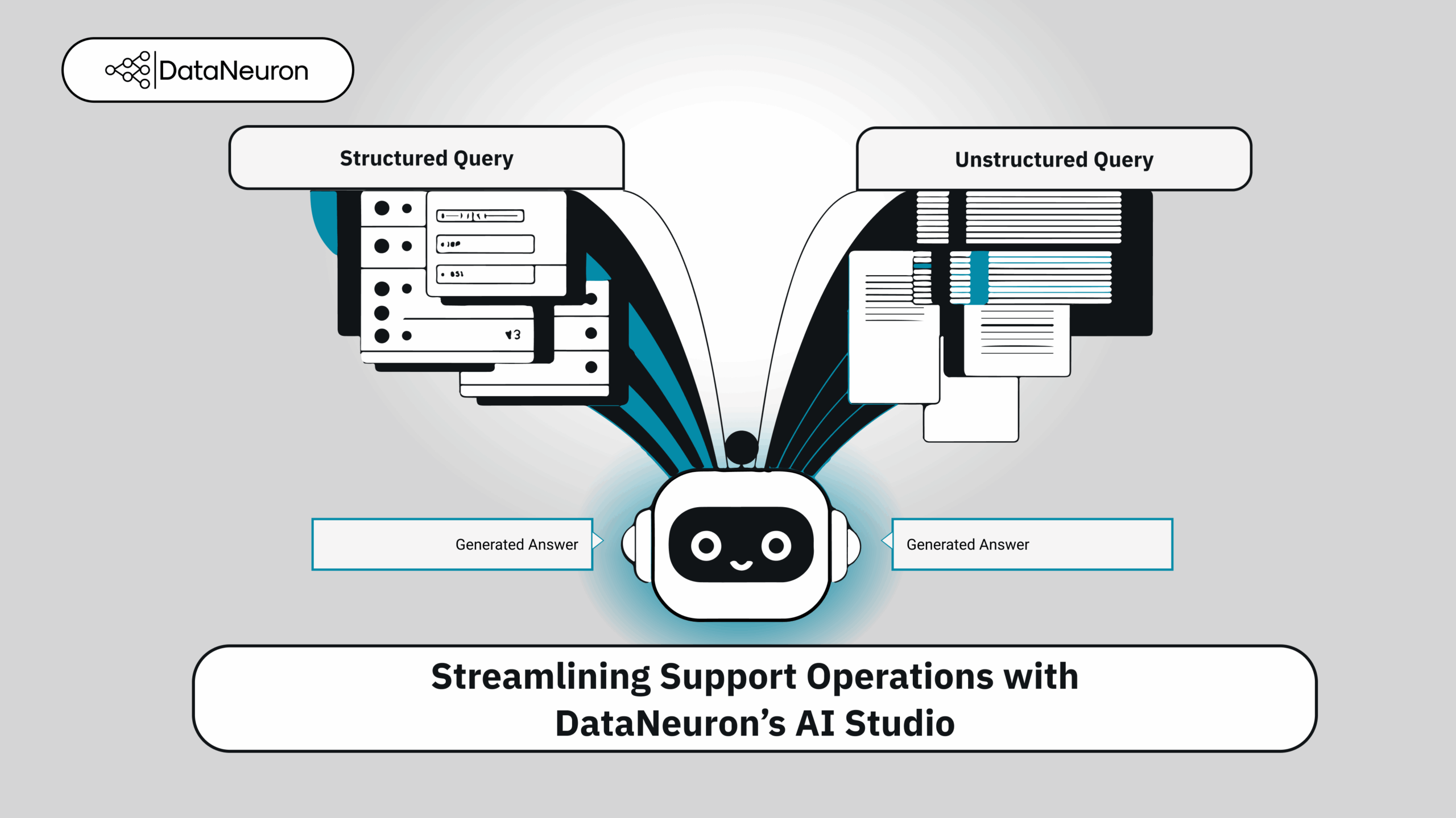
A leading D2C business in India and international markets, renowned for its home and sleep products, aimed to enhance customer support. As a major retailer of furniture, mattresses, and home furnishings, they faced a major challenge: inefficiency inhandlingahighvolumeofdiversecustomerinquiriesaboutproductdetails,orderstatus,andpolicies,resultingin slow response times and customer frustration. The company required a solution capable of understanding and responding to definitive customer queries, an area where existing chatbot solutions had fallen short.
The DataNeuron Solution: Smart Query Handling with LLM Studio
To solve this, the team implemented a smart, hybrid retrieval solution using DataNeuron’s LLM Studio, built to understand and respond to diverse customer queries, regardless of how or where the data was stored.
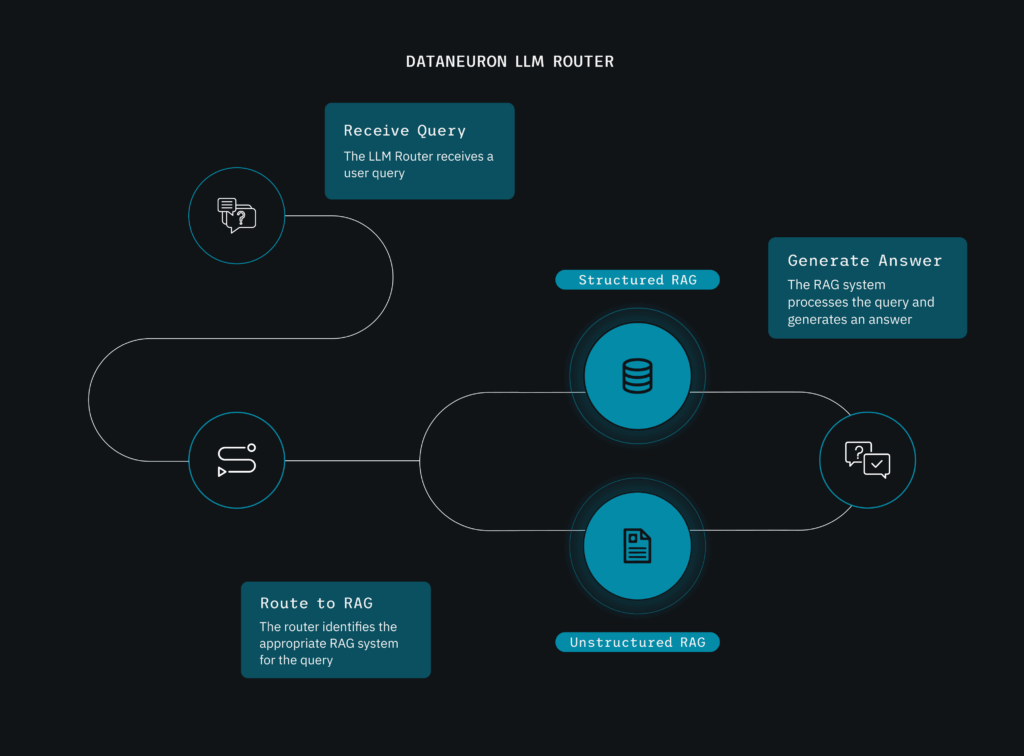
Step 1: Intelligent Classification with the LLM Router
The first stage was a classifier-based router that automatically determined whether a query required structured or unstructured information. For example:
Structured: “What is the price of a king-size bed?”
Unstructured: “What is the return policy if the product is damaged?”
The router leveraged a wide set of example queries and domain-specific patterns to route incoming questions to the right processing pipeline.
Once classified, queries flowed into one of two specialized pipelines:
Structured Query Pipeline: Direct Retrieval from Product Databases
Structured queries were translated into SQL and executed directly on product databases to retrieve precise product details, pricing, availability, etc. This approach ensured fast, accurate answers to data-specific questions.
Unstructured queries were handled via semantic vector search powered by DataNeuron’s RAG framework. Here’s how:
The question was converted into a vector embedding.
This vector was matched with the most relevant documents in the company’s vector database (e.g., policy documents, manuals).
The matched content was passed to a custom LLM to generate grounded, context-aware responses.
Studio Benefits: Customization, Evaluation, and Fallbacks
The LLMs used in both pipelines were customized via LLM Studio, which offered:
Fallback mechanisms when classification confidence was low, such as routing queries to a human agent or invoking a hybrid LLM fallback.
Tagging and annotation tools to refine training data.
Built-in evaluation metrics to monitor performance.
DataNeuron’s LLM Router, transformed our support: SQL‑powered answers for product specs and semantic search for policies now resolve 70% of tickets instantly, cutting escalations and driving our CSAT, all deployed in under two weeks.
– Customer Testimony
The DataNeuron Edge
DataNeuron LLM Studio automates model tuning with:
Built-in tools specifically for labeling and tagging datasets.
LLM evaluations to compare performance before and after tweaking.
Substantive changes introduced:
Specifically stated “service” and “cancellation” to address comments.
Highlighted the “Router capability dataset with lots of questions” to highlight the importance of data diversity for the classifier.
Detailed the process of the “Structure RAG” pipeline, including natural language to SQL and back to natural language.
We’ve all seen how Large Language Models (LLMs) have revolutionized tasks, from answering emails and generating code to summarizing documents and navigating chatbots. In just one year, market growth increased from $3.92 billion to $5.03 billion in 2025, driven by the transformation of customer insights, predictive analytics, and intelligent automation.
However, not every AI challenge can(or should) be solved with a single, monolithic model. Some problems demand a laser-focused expert LLM, customized to your precise requirements. Others call for a team of specialised models working together like humans do.
At DataNeuron, we recognize this distinction in your business needs and empower enterprises with both advanced fine-tuning options and flexible multi-agent systems. Let’s understand how DataNeuron’s unique offerings set a new standard.
What is a Fine-Tuned LLM, Exactly?
Consider adopting a general-purpose AI model and training it to master a specific activity, such as answering healthcare queries, insurance questions, or drafting legal documents. That is fine-tuning. Fine-tuning creates a single-action specialist, an LLM that consistently delivers highly accurate, domain-aligned responses.
Publicly available models (such as GPT-4, Claude, and Gemini) are versatile but general-purpose. They are not trained using your confidential data. Fine-tuning is how you close the gap and turn generalist LLMs into private-domain experts.
With fine-tuning, you use private, valuable data to customize an LLM to your unique domain needs.
Medical information (clinical notes, patient records, and diagnostic protocols is safely handled for HIPAA/GDPR compliance.
Financial compliance documents
Legal case libraries
Manufacturing SOPs
Fine-Tuning Options Offered by DataNeuron
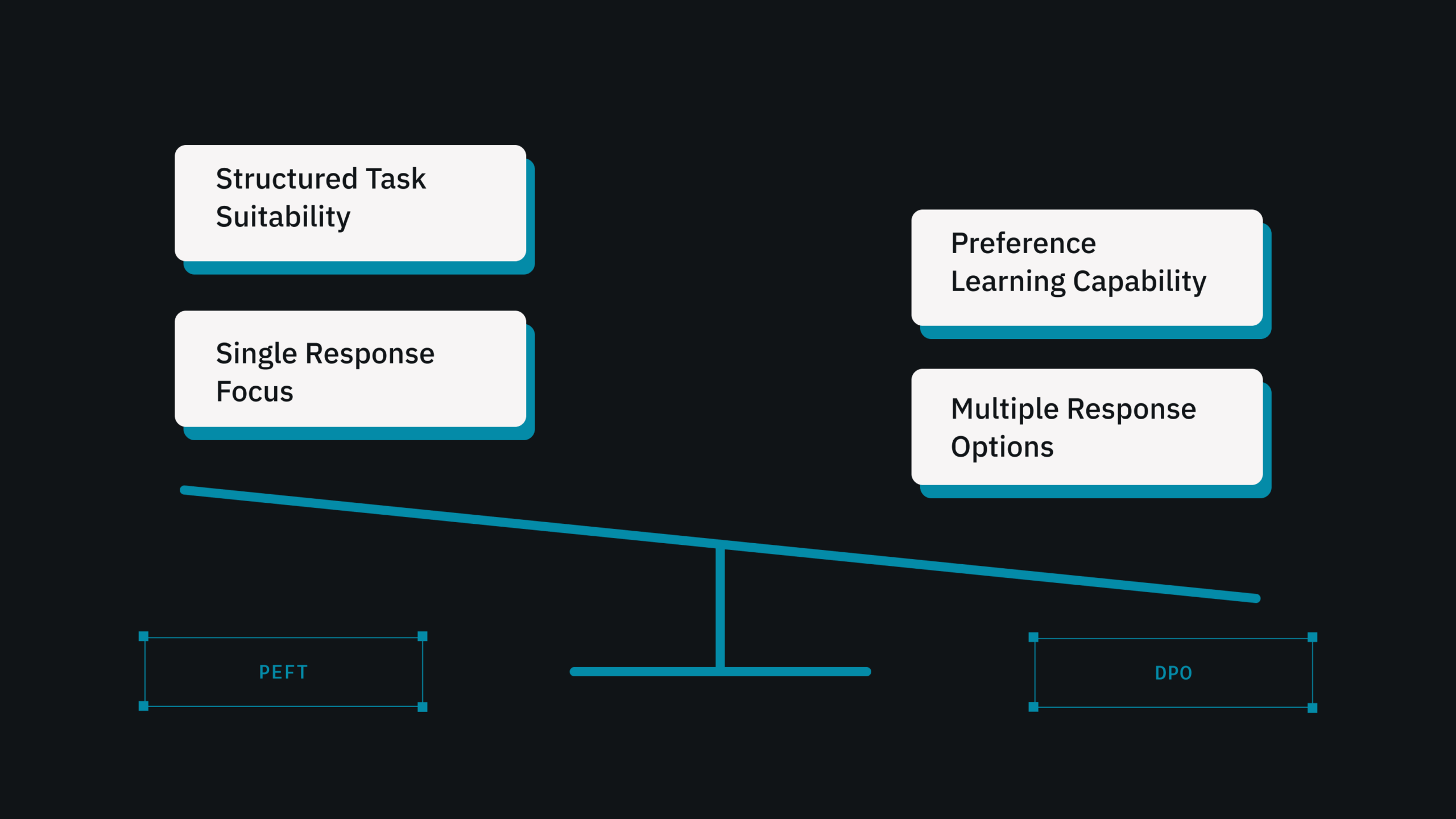
Parameter-Efficient Fine-Tuning: PEFT is a more efficient fine-tuning method that only changes a portion of the model’s parameters. PEFT (Prefix-Tuning for Efficient Adaptation of Pre-trained BERT) is a widely used approach with promising outcomes.
Direct Preference Optimization: DPO aligns models to human-like preferences and ranking behaviors. Ideal for picking multiple types of responses.
DataNeuron supports both PEFT and DPO workflows, providing scalable, enterprise-grade model customisation. These solutions enable enterprises to quickly adapt to new use cases without requiring complete model retraining.
If your work does not change substantially and the responses follow a predictable pattern, fine-tuning is probably your best option.
What is a Multi-Agent System?
Instead of one expert, you have a group of agents performing tasks in segments. One person is in charge of planning, another collects data, and another double-checks the answer. They work together to complete a task. That’s a multi-agent system, multiple LLMs (or tools) with different responsibilities that work together to handle complicated operations.
A multi-agent system involves multiple large language models (LLMs) or tools, each with distinct responsibilities, collaborating to execute complex tasks.
At DataNeuron, our technology is designed to allow both hierarchical and decentralized agent coordination. This implies that teams may create workflows in which agents take turns or operate simultaneously, depending on the requirements.
Agent Roles: Planner, Retriever, Executor, and Verifier
In a multi-agent system, individual agents are entities designed to perform specific tasks as needed. While the exact configuration of agents can be built on demand and vary depending on the complexity of the operation, some common and frequently deployed roles include:
Planner: Acts like a project manager, responsible for defining tasks and breaking down complex objectives into manageable steps.
Retriever: Functions as a knowledge scout, tasked with gathering necessary data from various sources such as internal APIs, live web data, or a Retrieval-Augmented Generation (RAG) layer.
Executor: Operates as the hands-on worker, executing actions on the data based on the Planner’s instructions and the information provided by the Retriever. This could involve creating, transforming, or otherwise manipulating data.
Verifier: Plays the role of a quality assurance specialist, ensuring the accuracy and validity of the Executor’s output by identifying discrepancies, validating findings, and raising concerns if issues are detected.
These roles represent a functional division of labor that enables multi-agent systems to handle intricate tasks through coordinated effort. The flexibility of such systems allows for the instantiation of these or other specialized agents as the specific demands of a task dictate.
Key Features:
Agents may call each other, trigger APIs, or access knowledge bases.
They could be specialists (like a search agent) or generalists.
Inspired by how individuals delegated and collaborated in teams.
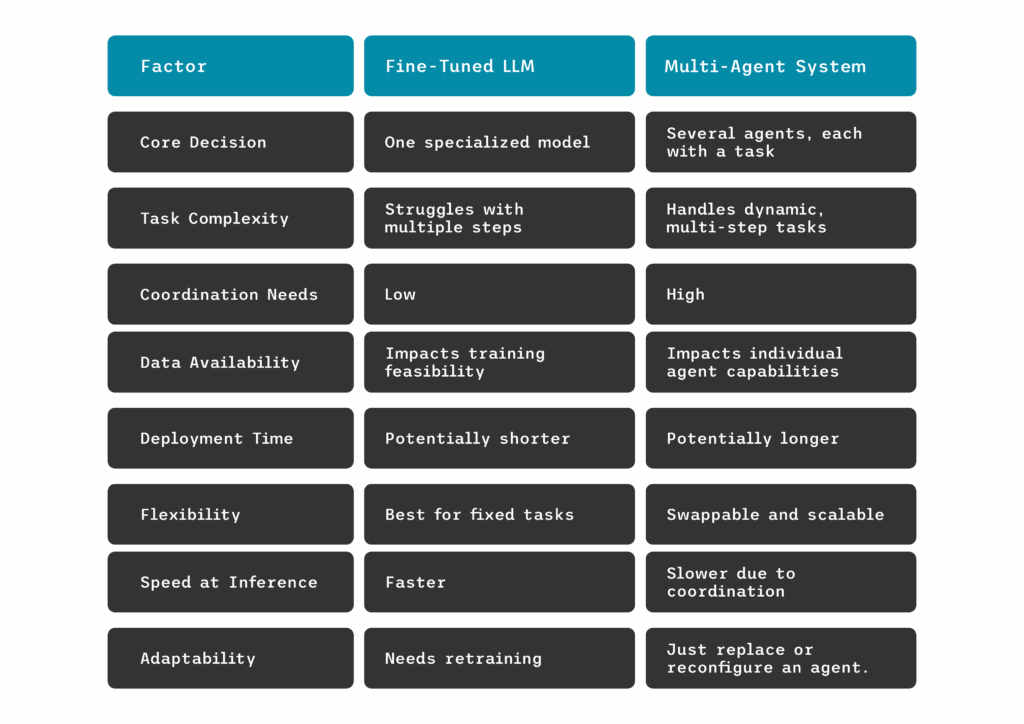
Choosing Between Fine-Tuned LLMs and Multi-Agent Systems: What Points to Consider
Data In-Hand
If you have access to clean, labeled, domain-specific data, a fine-tuned LLM can generate high precision. These models thrive on well-curated datasets and learn only what you teach them.
Multi-agent systems are better suited to data that is dispersed, constantly changing, or unstructured for typical fine-tuning. Agents such as retrievers may extract essential information from APIs, databases, or documents in real time, eliminating the need for dataset maintenance.
Task Complexity
Consider task complexity as the number of stages or moving pieces involved. Fine-tuned LLMs are best suited for targeted, repeated activities. You teach them once, and they continuously perform in that domain.
However, when a job requires numerous phases, such as planning, retrieving data, checking outcomes, and initiating actions, a multi-agent method is frequently more suited. Different agents specialize and work together to manage the workflow from start to finish.
Need for Coordination
Fine-tuned models may be quite effective for simple reasoning, especially when the prompts are well-designed. They can use what they learnt in training to infer, summarize, or produce.
However, multi-agent systems excel when the task necessitates more back-and-forth reasoning or layered decision-making. Before the final product goes into production, a planner agent breaks down the task, a retriever recovers information, and a validator verifies for accuracy.
Time to Deploy
Time is typically the biggest constraint. Fine-tuning needs some initial investment: preparing data, training the model, and validating results. It’s worth it if you know the assignment will not change frequently.
Multi-agent systems provide greater versatility. You can assemble agents from existing components to get something useful up and running quickly. Need to make a change? Simply exchange or modify an agent; no retraining is required.
Use Cases: Fine-Tune Vs. Multi-Agent
The best way to grasp a complicated decision is through a few tangible stories. So here are some real-world scenarios that make the difference between fine-tuned LLMs and multi-agent systems as clear as day.
Scenario 1: Customer Support Chatbot
Company: HealthTech Startup
Goal: Develop a chatbot that responds to patient queries regarding their platform.
Approach: Fine-Tuned LLM
They trained the model on:
Historical support tickets
Internal product documentation
HIPAA-compliant response templates
Why it works: The chatbot provides responses that read on-brand, maintain compliance rules, and do not hallucinate because the model was trained in the company’s precise tone and content.
Scenario 2: Market Research Automation
Business: Online Brand
Objective: Be ahead of the curve by automating product discovery.
Approach: Multi-Agent System
The framework includes:
Search Agent to crawl social media for topically relevant items
Sentiment and Pattern Recognition Analyzer Agent
Strategic Agent to advise on product launch angles
Why it works: The system constantly monitors the marketplace, learns to adjust to evolving trends, and gives actionable insights that are free from human micromanagement.
At DataNeuron, we built our platform to integrate fine-tuned intelligence with multi-agent collaboration. Here’s what it looks like: Various agents, both pre-built and customizable, can be used for NLP tasks like NER, document search, and RAG. Built-in agents offer convenience for common tasks, while customizable agents provide flexibility for complex scenarios by allowing fine-tuning with specific data and logic. The choice depends on task complexity, data availability, performance needs, and resources. Simple tasks may suit built-in agents, whereas nuanced tasks in specialized domains often benefit from customizable agents. Advanced RAG applications frequently necessitate customizable agents for effective information retrieval and integration from diverse sources.
So, whether your activity is mundane or dynamically developing, you get the ideal blend of speed, scalability, and intelligence. You don’t have to pick sides. Instead, choose what best suits your business today. We are driving this hybrid future by making it simple to design AI that fits your workflow, not the other way around.
The adoption of Large Language Models (LLMs) has transformed how industries function, unlocking capabilities from customer support automation to improving human-computer interactions. Their adoption is soaring, with MarketsandMarkets projecting the global LLM market to grow at a compound annual growth rate (CAGR) of over 35% in the next five years. Yet, many businesses that rush to adopt these models are discovering a critical insight: the model itself isn’t what sets you apart your data does.
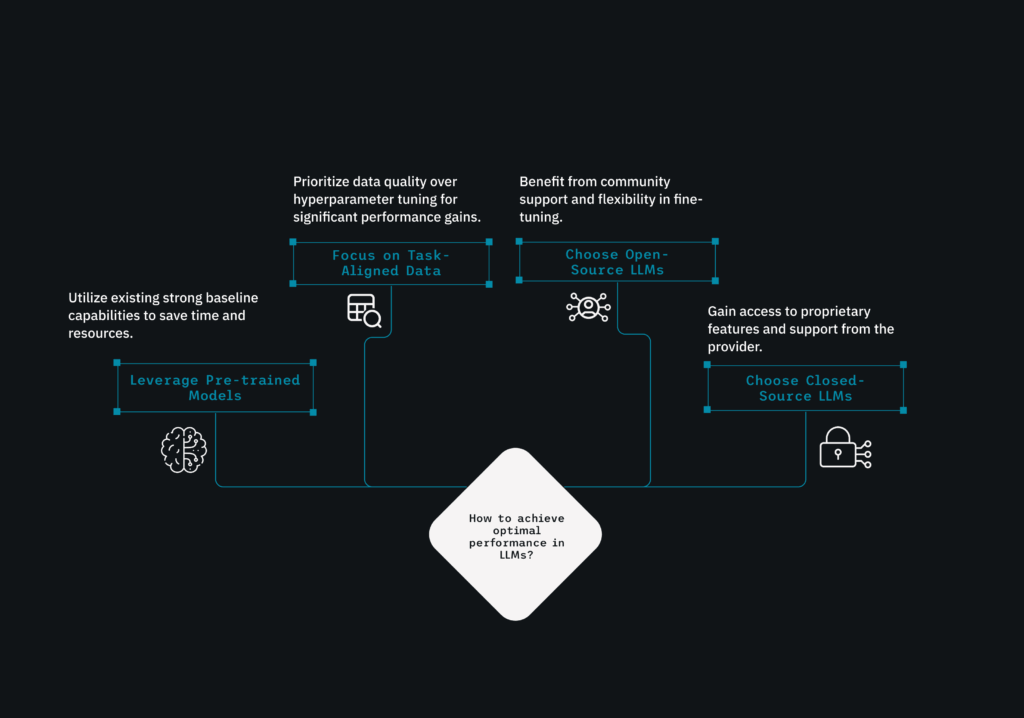
While impressive, pre-trained LLMs are fundamentally generalists. They are trained on a broad, diverse pool of public data, making them strong in language understanding but weak in context relevance. A well-curated dataset ensures that an LLM understands industry jargon, complies with regulatory constraints, and aligns with the client’s vision.
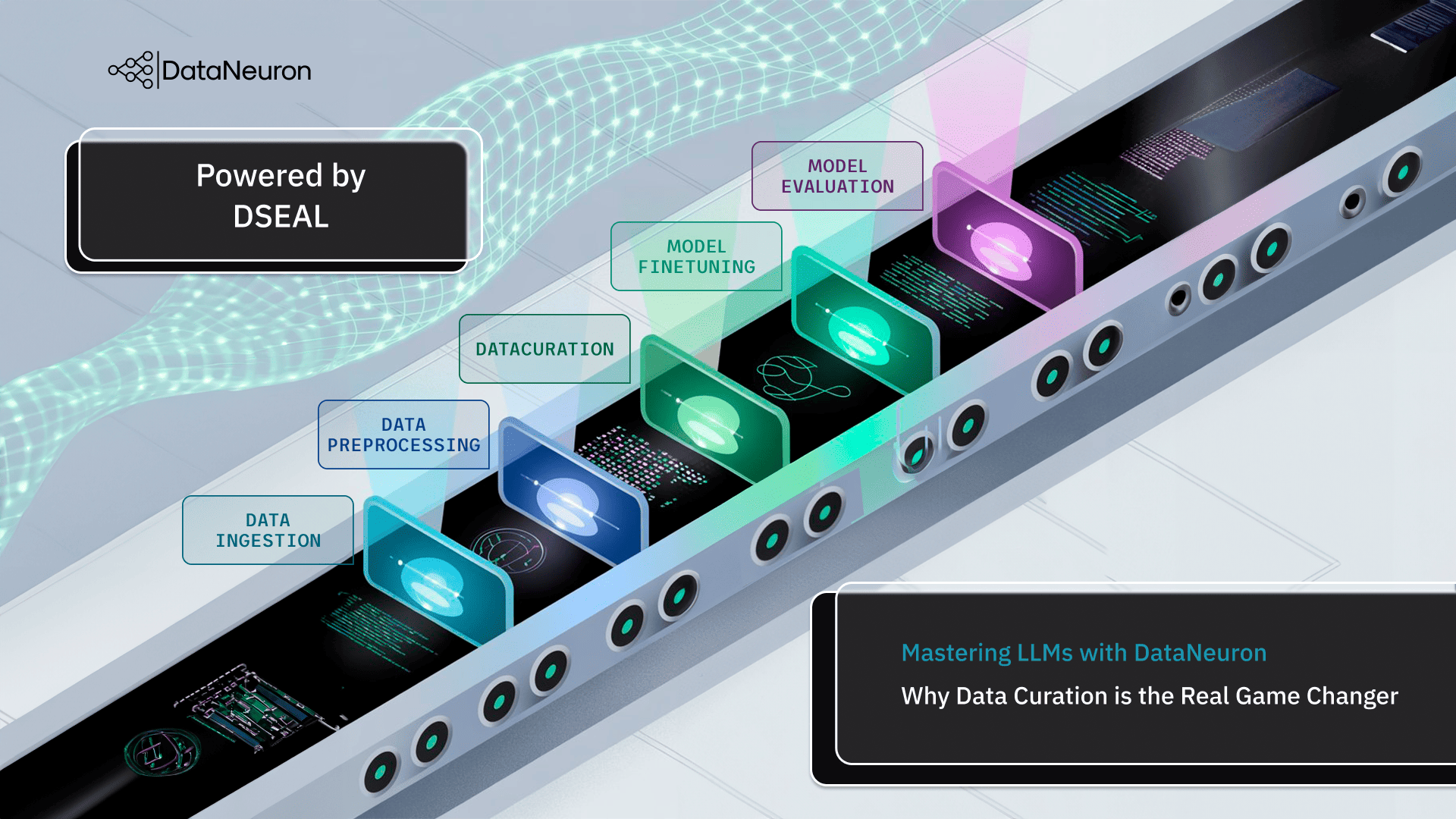
At DataNeuron, we’ve built our approach around this idea. Our Divisive Sampling for Efficient Active Learning (DSEAL) framework redefines what it means to prepare data for fine-tuning. Rather than throwing thousands of generic examples at a model, DSEAL enables the creation of focused, instructive, and diverse datasets while maintaining speed and confidentiality with minimal manual intervention.
Why Data Curation is the Hidden Engine Behind Fine-Tuning
You wouldn’t train a legal assistant with engineering textbooks. Yet many enterprises expect LLMs trained on internet data to perform highly specialized tasks with minimal adaptation. This mismatch leads to a familiar set of issues: hallucination, shallow reasoning, and a lack of domain fluency.
The data that the model has or hasn’t seen contributes to these challenges. Fine-tuning a model with domain-specific examples allows it to grasp the nuances of your vocabulary, user expectations, and compliance norms. Nonetheless, fine-tuning is sometimes misinterpreted as a process concentrated on coding. In practice, 80% of successful LLM fine-tuning depends on one factor: the correct data. We provide two fine-tuning options: PEFT and DPO, both of which are fully dependent on the quality of the incoming dataset.
Without sufficient curation, fine-tuning can provide biased, noisy, or irrelevant results. For instance, a financial LLM trained on poorly labeled transaction data may misidentify fraud tendencies. A healthcare model analyzing unstructured clinical notes may make harmful recommendations.
LLM Customization Starts with Curation, Not Code
Enterprises often approach LLM customization like a software engineering project: code first, optimize later. But with LLMs, data>code is where the transformation begins. Fine-tuning doesn’t start with scripts or API’s, it begins with surfacing the right example from your data sources. Whether you employ open-source models or integrate with closed APIs, the uniqueness of the dataset makes our platform an ideal place to collaborate. Your support tickets, policy documents, email logs, and chat exchanges include an array of concealed data. However, they are distorted, inconsistent, and unstructured.
Curation turns this raw material into clarity. It is the process of identifying relevant instances, clearing up discrepancies, and aligning them with task requirements. At scale, it enables LLMs to progress from knowing a lot to understanding what matters.
This is why our clients don’t start their AI journey by deciding whether to use GPT or Llama; they begin by curating a dataset that reflects the tasks they care about. With the correct dataset, any model can be trained into a domain expert.
DataNeuron’s platform automates 95% of dataset creation, allowing businesses to prioritize strategic sampling and validation over human labeling. And the output? DataNeuron’s prediction API enables faster deployment, improved accuracy, and smoother integration.
Why Scaling Data Curation is Challenging Yet Important
For most companies, data curation is a bottleneck. It’s easy to underestimate how labor-intensive this procedure may be. Manually reviewing text samples, labeling for context, and ensuring consistency is an inefficient procedure that cannot be scaled.
We focus on quality over volume. Models trained using irrelevant or badly labeled samples frequently perform worse than models that were not fine-tuned at all. Add to this the complexities of data privacy, where sensitive internal documents cannot be shared with external tools, and most businesses find themselves trapped.
This is where we invented the DSEAL framework, which revolutionized the equation.
How DataNeuron’s DSEAL Framework Makes High-Quality Curation Possible
DSEAL is our solution to the most common problems in AI data preparation. DSEAL solves a basic issue in machine learning: the inefficiency and domain limitation of classic active learning methods. It’s a system designed to automate what’s slow, eliminate what’s unnecessary, and highlight the things that matter.
What makes DSEAL different from others?
95% Curation Automation: From ingestion to labeling, the system does the majority of the labor.
Task-aligned sampling: DSEAL strategically samples across edge cases, structures, and language trends rather than random examples.
Instruction-First Formatting: The curated data is organized to match instruction-tuned models, increasing relevance and accuracy.
Private by Design: All processes run inside the enterprise environment; no data leaves your perimeter.
The change from brute-force annotation to smart, minimum, domain-adaptive sampling distinguishes DSEAL in today’s noisy and model-saturated market.
Key Takeaways
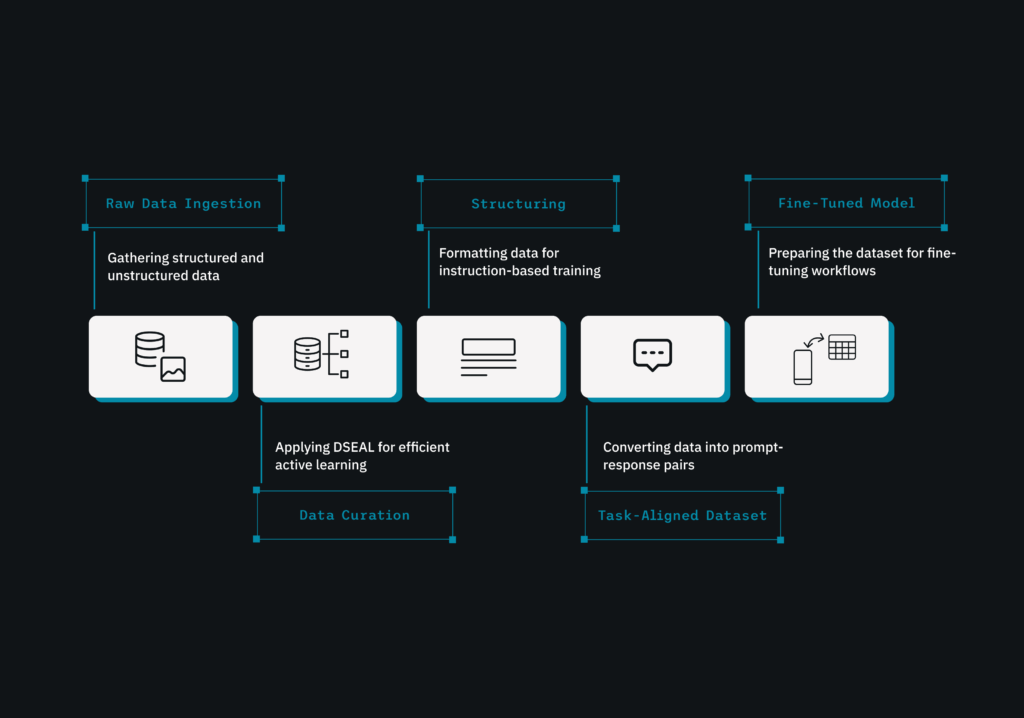
From raw to model-ready in four steps:
Raw Data Ingestion: Whether it’s email threads or chat logs, the data enters the system untouched.
Cleaning and Structuring: We remove duplicates, normalize formats, and extract only the content that is relevant to your aims.
Instruction formatting: It involves converting data into prompt-response pairs or structuring it for preference-based training.
Model-Ready Dataset: The completed dataset is ready for fine-tuning procedures, complete with traceability and metrics.
Fine-tuning is no longer about model design but about context and detail. Your business already has everything it needs to create world-class AI: its data. The difficulty lies in converting the data into a structured, informative resource from which an LLM may learn.
With DSEAL, DataNeuron turns curation from a manual bottleneck to a strategic advantage. We help you go from data chaos to clarity, providing your models the depth and focus they require to operate in the real world.
The sample is a collection of people, things, or things used in the study that is taken for analysis from a wider population. To enable us to extrapolate the research sample’s findings to the entire population, the sample must be representative of the population.
Let’s go through a real-world scenario.
We’re looking for Mumbai’s adult population’s average annual salary. Up till 2022, Mumbai has a population of about 30 million. Males and females in this population would roughly be split 1:1 (these are simple generalizations), and they might have different averages. Similarly, there are numerous more ways in which various adult population groupings may have varying income levels. As you may guess, it is incredibly difficult to determine the average adult income in Mumbai.
Since it’s impossible to reach every adult in the whole population, what can be the solution? We can collect numerous samples and determine the average height of the people in the chosen samples.
How can we take a Sample?
Taking the same scenario from above, imagine we only take samples from the people in managerial positions. This won’t be regarded as a decent sample because, on generalizing, a manager earns more than the average adult, and it will provide us with a poor estimation of the income of the average adult. A sample must accurately reflect the universe from which it was drawn.
There are various different potential solutions, but we’ll be looking at three major techniques.
Sampling strategies :
Most uncertain probability
Most certain data points
The basic mixture from different confidence intervals
Most Uncertain Probability
The aim behind uncertainty sampling is to focus on the data item that the present predictor is least certain about. To put it another way, uncertainty sampling typically finds points that are located near thWhat is Sampling?
The sample is a collection of people, things, or things used in the study that is taken for analysis from a wider population. To enable us to extrapolate the research sample’s findings to the entire population, the sample must be representative of the population.
Let’s go through a real-world scenario.
We’re looking for Mumbai’s adult population’s average annual salary. Up till 2022, Mumbai has a population of about 30 million. Males and females in this population would roughly be split 1:1 (these are simple generalizations), and they might have different averages. Similarly, there are numerous more ways in which various adult population groupings may have varying income levels. As you may guess, it is incredibly difficult to determine the average adult income in Mumbai.
Since it’s impossible to reach every adult in the whole population, what can be the solution? We can collect numerous samples and determine the average height of the people in the chosen samples.
How can we take a Sample?
Taking the same scenario from above, imagine we only take samples from the people in managerial positions. This won’t be regarded as a decent sample because, on generalizing, a manager earns more than the average adult, and it will provide us with a poor estimation of the income of the average adult. A sample must accurately reflect the universe from which it was drawn.
There are various different potential solutions, but we’ll be looking at three major techniques.
Sampling strategies :
Most uncertain probability
Most certain data points
The basic mixture from different confidence intervals
Most Uncertain Probability
The aim behind uncertainty sampling is to focus on the data item that the present predictor is least certain about. To put it another way, uncertainty sampling typically finds points that are located near the decision boundary of the current model.
Uncertainty Sampling
Assume that a student is preparing for an exam and has 1000 questions to go through. The student only has time to go through 100 of them. Naturally, the student should prepare 100 questions on which the individual is least confident. With the new questions, students should get smarter, and faster.
Most Certain Data Points
This method chooses the data points with the highest certainty ie. data points that are predicted by the model with the highest confidence. These data points have maximum chances of getting correctly predicted by the model. Such data points may or may not add a lot of new information to the model learning.
Basic mixture of different Confidence Intervals
Data points are grouped according to their confidence scores, and sampling is done from all of these intervals or groups. This way, we can make sure that no kind of data is missed out upon. This ensures that the sampled data points are having a balance of certain and uncertain data points. This way the model can learn the decision boundary well without missing out on already learned information.
Code
Now, let’s use these sampling methods and see their application using a simple code in Python!
We’ll be working with a binary classification problem, using two datasets:
IMDB Movie Review Dataset for sentiment analysis. Two classes in this dataset: Positive, Negative
Emotion Dataset. Two classes in this dataset: Joy, Sadness
We have performed this experiment on Jupyter Notebook.
Loading Data & Preprocessing
The availability of data is always a determining factor in the field of machine learning, so loading data should be done first. After loading the dataset and the necessary modules, the dataframe should be looking like this.
Clean the data by replacing all occurrences of breaks with single white space.
for idx in range(len(df['review'])):
df['review'][idx] = df['review'][idx].replace('<br /><br />', ' ')
For ease of the experiment, we’re using 10k paragraphs out of the whole dataset of 50k paragraphs.
Since the train and test sets have been constructed, the pipeline can be instantiated. The pipeline consists of three steps: data transformation, resampling, and model creation at the end.
# The resulting matrices will have the shape of (`nr of examples`, `nr of word n-grams`)
vectorizer = CountVectorizer(ngram_range=(1, 5))
X_100_train = vectorizer.fit_transform(df_100_train.review)
X_stage1_test = vectorizer.transform(df_stage1_test.review)
X_test = vectorizer.transform(df_test.review)
labelencoder = LabelEncoder()
df_100_train['sentiment'] = labelencoder.fit_transform(df_100_train['sentiment'])
df_stage1_test['sentiment'] = labelencoder.transform(df_stage1_test['sentiment'])
df_test['sentiment'] = labelencoder.transform(df_test['sentiment'])
Before moving on to sampling strategies, an initial model is trained
1000 or more paragraphs are picked from a window of probability with the highest degree of uncertainty. These 1000 paragraphs are sorted increasingly in a dataframe. Then we compute the predicted probability’s mean value.
The index of the row with the predicted probability value closest to the mean value is calculated.
The paragraph sets are chosen using the mean value index row (Half of them from greater than part and half of them from less than part of the probability). To choose the most uncertain sets of paragraphs, use the same method as minimizing and maximizing the uncertain probability window range.
#index of the row closest to the mean value of predicted probability
mid_idx = int(len(df_uncertain_sorted)/2)
mean_idx = mid_idx-12
df_uncertain_sorted['predict_proba'].mean()
[Out]: 0.4936057560087512
num_of_para = [100,200,300,400,500,600,700,800,900,1000]
score_uncertain_list = []
for para in num_of_para:
para_idx = int(para/2)
#training set
df_uncertain_new = df_uncertain_sorted.iloc[mean_idx-para_idx:mean_idx+para_idx]
#preprocessing
X_train_uncertain = vectorizer.transform(df_uncertain_new.review)
#defining the classifier
logreg_uncertain = LogisticRegression()
#training the classifier
logreg_uncertain.fit(X=X_train_uncertain, y=df_uncertain_new['sentiment'].to_list())
#calculating the accuracy score on the test set
score_uncertain = logreg_uncertain.score(X_test, df_test['sentiment'].to_list())
score_uncertain_list.append(score_uncertain)
score_uncertain_list
[Out]: [0.547, 0.5845, 0.584, 0.612, 0.6215, 0.6335, 0.6415, 0.663, 0.659, 0.6755]
Most Certain Probability Sampling
The dataframe with 7900 paragraphs is sorted in descending order of their predicted probabilities. The top [100,200,300,400,500,600,700,800,900,1000] sets of paragraphs are selected as the most certain paragraphs.
num_of_para = [100,200,300,400,500,600,700,800,900,1000]
score_certain_list = []
for para in num_of_para:
#training set
df_certain = df_proba_sorted[:para]
#preprocessing
X_train_certain = vectorizer.transform(df_certain.review)
#defining the classifier
logreg_certain = LogisticRegression()
#training the classifier
logreg_certain.fit(X=X_train_certain, y=df_certain['sentiment'].to_list())
#calculating the accuracy score on the test set
score_certain = logreg_certain.score(X_test, df_test['sentiment'].to_list())
score_certain_list.append(score_certain)
score_certain_list
[Out]: [0.5215, 0.54, 0.536, 0.5755, 0.5905, 0.6245, 0.641, 0.6735, 0.7355, 0.7145]
Confidence Interval Grouping Sampling
In this method, the 25th and 75th percentile of the predicted probabilities are calculated. Then the 7900 paragraphs are separated into 3 groups.
From these 3 groups [100,200,300,400,500.600,700.800.900,1000] sets of paragraphs are sampled out according to these fractions:
#calculating the 25th and 75th percentile
proba_arr = df_proba['predict_proba']
percentile_75 = np.percentile(proba_arr, 75)
percentile_25 = np.percentile(proba_arr, 25)
print("25th percentile of arr : ",
np.percentile(proba_arr, 25))
[Out]: 25th percentile of arr : 0.28084100127515504
print("75th percentile of arr : ",
np.percentile(proba_arr, 75))
[Out]: 75th percentile of arr : 0.7063559972435552
#grouping of the paragraphs for following window
# group 1 : >= 75
df_group_1 = df_proba[df_proba['predict_proba'] >= percentile_75]
# group 2 : <75 and >= 25
df_group_2 = df_proba[(df_proba['predict_proba'] >= percentile_25) & (df_proba['predict_proba'] < percentile_75)]
# group 3 : < 25
df_group_3 = df_proba[(df_proba['predict_proba'] < percentile_25)]
df_group_1.shape, df_group_2.shape, df_group_3.shape
[Out]: ((1975, 3), (3950, 3), (1975, 3))
Four different models are then trained on each set of paragraphs for each of the 3 sampling techniques. [total 10 x 3 = 30 models]. The accuracy score is calculated for each of the cases by fitting the models on the 2000-paragraph test set.
num_of_para = [100,200,300,400,500,600,700,800,900,1000]
score_conf_list = []
#fractions
frac1 = 0.4
frac2 = 0.3
frac3 = 0.3
#sampling paragraphs from the 3 groups
df_group_1_frac = df_group_1.sample(frac=frac1, random_state=1).reset_index(drop = True)
df_group_2_frac = df_group_2.sample(frac=frac2, random_state=1).reset_index(drop = True)
df_group_3_frac = df_group_3.sample(frac=frac3, random_state=1).reset_index(drop = True)
for para in num_of_para:
#sampling paragraphs from the 3 groups to build the training set
df_group_1_new = df_group_1_frac[:int(frac1 * para)]
df_group_2_new = df_group_2_frac[:int(frac2 * para)]
df_group_3_new = df_group_3_frac[:int(frac3 * para)]
df_list = [df_group_1_new, df_group_2_new, df_group_3_new]
#training set
df_conf = pd.concat(df_list).reset_index(drop = True)
#preprocessing
X_train_conf = vectorizer.transform(df_conf.review)
#defining the classifier
logreg_conf = LogisticRegression()
#training the classifier
logreg_conf.fit(X=X_train_conf, y=df_conf['sentiment'].to_list())
#calculating the accuracy score on the test set
score_conf = logreg_conf.score(X_test, df_test['sentiment'].to_list())
score_conf_list.append(score_conf)
score_conf_list
[Out]: [0.6525, 0.6835, 0.7235, 0.7525, 0.766, 0.7735, 0.778, 0.7875, 0.796, 0.807]
Results and Conclusion
The accuracies of the three sampling strategies can now be compared, and it is clear that a combination of different confidence intervals performs better than the others. This shows that along with learning new information from uncertain paragraphs the model also requires retaining the previously learned information. Therefore a balance of data from different confidence intervals helps the model learn, maximizing the resulting overall accuracy.
Teams in nearly all fields, spend a majority of their time on research and finding chunks of important information from the huge bulk of unfiltered data and documents that is present within the organization. This process is very time consuming and tedious.
In fields like data science and machine learning, getting annotated data is one of the biggest hurdles and one that the teams tend to spend the most time on.
Apart from this, data annotation can often prove to be expensive as well. Multiple human annotators might need to be hired and this can increase the overall cost of the project.
The DataNeuron platform enables organizations to get accurately annotated data, while minimizing the time, effort and cost expenditure.
DataNeuron’s Semi-Supervised Annotation
What does the platform provide?
The user is provided with an option to define a project structure, which is not limited to a flat classification hierarchy but can incorporate a multilevel hierarchical structure as well with indefinite levels of parent-child relationships between nodes.
This aids research, since the data is essentially divided into groups and further sub-groups depending on the user preference and defined structure which enables the team to adopt a “top-down” approach for getting to the desired data.
The platform takes a semi-supervised approach to data annotation in the sense that the user is required to annotate only about 5–10% of the entire data and the platform annotates the remaining data automatically for the user by detecting contextual similarity and patterns in the data.
How the semi-supervised approach works?
Even for the 5–10% of the total data that still needs to be annotated, the time and effort spent is reduced by a large margin by adopting a suggestion-based validation technique.
The platform provides auto-labeling to the users and suggests the paragraphs that are likely to belong to a specific class based on label heuristics and contextual filtering algorithm; users have to accept or reject at the validation stage.
The semi-supervised approach for validation is broken down into stages:
In the first stage, the user is provided with suggestions based on an intelligent context-based filtering algorithm. The validations done by the user in the first stage are used to improve the accuracy of the filtering algorithm used to provide suggestions for validations.
In the second stage the validation is then further broken down into ‘batches’. This process is repeated for each batch of the second stage, i.e. the validations done in each batch are used to increase the accuracy of the filtering algorithm for the succeeding batch.
This breaks down the problem of annotating a data point into a “one-vs-all” problem which makes it far easier for the user to arrive at an answer(annotation) than if they had to consider all the classes (which might be a huge number depending on the complexity of the problem) for making each individual annotation.
Our platform is a “No-Code” platform and anyone with basic knowledge of the domain they are working on can use the platform to its maximum potential.
Testing On Various Datasets
The platform chooses from among multiple models trained on the same training data, to provide the best possible results to the users.
The average K-Fold accuracy of the model is presented as the final accuracy of the trained model.
We incur a relatively small drop in accuracy as a result of the decreased size of the training data as highlighted. This dip in accuracy is within 12% and can be controlled by the user by annotating more data, or choosing to add seed paragraphs during the validation or feedback and review stage.
Comparisons with an In-House Project
Difference in Paragraphs Annotated. We observe it is possible to reduce annotation effort by up to 96%.
Difference in Time Required. We observe it is possible to reduce time required for annotation by up to 98%.
Difference in Accuracy.
We observe that the DataNeuron platform can decrease the annotation time up to 98%. This vastly decreases the time and effort spent annotating huge amounts of data, and allows teams to focus more on the task at hand.
Additionally it can also help reduce the Subject Matter Expert effort up to 96%, while incurring a marginal cost. Our platform also helps reduce the overall cost of the project by a significant margin, by nearly eradicating the need for data labeling/annotation teams.
In most cases, the need for appointing an SME is also diminished, as the process of annotation is made much simpler and easier and anyone with knowledge of the domain and the project they are working on can be able to perform the annotations through our platform.
As the volume of data has exploded in recent years, collecting an accurate and extensive amount of annotated data is one of the biggest hurdles in the field of data science and machine learning [1]. There are various pre-existing methods which try to tackle this scarcity. However, these methods can still be costly and require SMEs. This paper proposes a novel active learning framework called Divisive Sampling and Ensemble Active Learning (DSEAL) which enables the users to create large, high-quality, annotated datasets with very less manual validations, thus strongly reducing annotation cost and effort. In this paper, we further provide a comparative study of performances of DSEAL with existing methods including Manual Annotation and Weak Supervision using a multiclass dataset. The results from the experiment show that DSEAL performs better than other studied solutions.
1 Introduction
Modern machine learning models have attained new state-of-the-art accuracies on a variety of traditionally difficult problems in recent years. The performances of these models are directly dependent on the quality and quantity of labeled training and testing datasets. With the advancement in the automation and commoditization of many ML models [2, 3, 4], researchers and organizations have shifted their focus in creating and acquiring high quality labeled datasets for various business purposes [3, 4].
However, the cost of labeling data quickly becomes a significant operational expense [5, 6]: collecting labels at scale requires carefully developing labeling instructions that cover a wide range of edge cases; training subject matter experts to carry out those instructions; waiting sometimes months or longer for the full results; and dealing with the rapid depreciation of datasets as applications shift and evolve.
To account for all the above problems, we are proposing a novel solution that can quickly label datasets using methods like divisive sampling and ensemble active learning
This paper is organized as follows: Section 2 discusses the techniques related to this work, including Manual Annotation and Weak Supervision. Section 3 describes our proposed framework and methodology. Section 4 describes the process of experiment with Section 5 presenting the results of our performance evaluation. Finally, Section 6 sets our conclusion.
2 Related Work
2.1 Manual Annotation
Manual Annotation is a human-supervised annotation technique where each example is labeled manually, by the SMEs. This requires a large number of SMEs to be hired specifically for labeling data, making it a costly solution. Further, the model may learn misleading patterns due to incorrect annotations arising from human errors and biases. Manual Annotation is also more prone to data privacy breaches as every data point is directly exposed to humans.
2.2 Weak Supervision
Weak Supervision is a part of the machine learning process, where higher-level and often noisier sources of supervision are used to programmatically generate a much larger set of labeled data that can be used in supervised learning [7]. The key idea in weak supervision is to train machine learning models utilizing information sources that are more accessible than hand-labeled data, even when that information is missing, inaccurate, or otherwise less reliable. Because labels are noisy, they are referred to as being “weak,” meaning that the data measurements they represent can have a margin of error which will have a significant negative impact on model performance as substantiated by a text classification experiment conducted by Zhang and Yang [12]. In [13], it is demonstrated that more samples are required for Probably Approximately Correct(PAC) identification of labels when uniform label noise is present in the framework.
Multiple weak learner labeling functions must be defined by the user for weak supervision. Labeling Functions are code snippets that map a data point to an estimated level. It will be hard to get decent results if a user does not have the appropriate labeling function heuristics or coding Knowledge.
3 DataNeuron Methodology – DSEAL
DSEAL stands for Divisive Sampling and Ensemble Active Learning. The cost of computation in semi-supervised learning is directly correlated with the volume of unlabeled data. Most of the time, data sizes can be very large, and it is not practical to use all of the unlabeled data. With DSEAL we can obtain high model performance even with a small portion of data. Our method of divisive sampling helps in strategically selecting only relevant data points. The number of validations decreases as more critical data points are suggested for validation by the model as it learns from each verified data point.
3.1 Divisive Sampling
DSEAL first trains machine learning algorithms on validated data and performs predictions on unlabelled data. Then a subset of paragraphs are selectively sampled from the unlabeled data. Strategy in sampling is to engage the most valuable data pints. In order to do so, we sample paragraphs from multiple classifiers. Multiple classifiers learn from each other’s mistakes and hence reduces the probability of error.
Further, we divide every classifier prediction into multiple groups. This is crucial since the model should perform well on any data seen in the real world, not just a certain sample. In our method, selections are made by dividing the data into groups of deciles on the basis of similarity scores. The probability of selection depends on which decile the paragraph resides in. Based on this, we perform random sampling for each decile.
Data with low confidence, closer to the decision boundary, will have higher probability for selection, and data with high confidence will have lower probability for selection. After sampling, validation is done by the user in a continuous manner. Each batch of validation is used to improve the accuracy of the filtering algorithm for the next batch. The human annotator only needs to validate a small number of the discriminative samples. This significantly minimizes the effort required for data labeling.
3.2 Ensemble Active Learning
The DSEAL method utilizes an ensemble Active Learning method consisting of semi-supervised and supervised machine learning algorithms. After every small batch of validation by user, all the model parameters are adjusted to take care of the user feedback. The recalibrated algorithms calculate prediction score from supervised model and similarity score from semi-supervised method for every unlabelled data point. In each batch, the models are additionally tested against a user validation. If a model consistently underperforms in successive batches, it is replaced by a new model trained completely from scratch using all available annotated data so far. Further a confidence score is assigned to every model in different batches, which is used to get final labeling for a new data point.
The annotations can be applied to all unlabeled data at once after the algorithmic annotations demonstrate good performance against user validations. If the model does not achieve the desired results after model training, the user can provide more training paragraphs or alter the project structure to remove some classes and then retrain the model to achieve better results. This method of learning through repetition in building models by making minor changes and progressively improving the performance helps DSEAL achieve better results with lesser efforts.
4 Experimental Procedure
4.1 The Dataset
For the purpose of the experiment, we have used the Contract Understanding Atticus Dataset (CUAD) [9]. The dataset contains corpus of commercial legal contracts that have been manually labeled under the supervision of experienced lawyers. We have randomly selected 10 types of legal clause classes for the text classification task. The dataset contains 4414 paragraphs.
A few (1000) noisy paragraphs were added to the dataset to make it more robust. The selected 10 classes are: Governing Law, Anti-assignment, Cap on Liability, Renewal Term, Insurance, IP Ownership Assignment, Change of Control, Volume Restriction, No-Solicit of Employees, Third Party Beneficiary. The class distribution is as follows:
4.2 Preparing the Train and Test Set
The dataset has all the similar classes grouped. Hence the dataset was shuffled to get paragraphs from all the classes if a random sample of the dataset was picked. The whole dataset is then split into training and testing sets: 80% for training and the rest of the 20% for testing.
4.3 Annotating the Paragraphs
In this step the paragraphs were annotated using three methods : Active Learning based on Uncertainty Measures, Weak Supervision, Manual Labeling, and DSEAL. We have used Snorkel (OSS) and Label Studio (Community) as the representative tools of Weak Supervision and Manual Labeling respectively. DataNeuron is the representative of DSEAL. Paragraphs were annotated using the three platforms separately.
At the end of the annotation process the same number of paragraphs annotated by each of the platforms were exported for training for a fair comparison. 4.4 Model Building
Here we have used a common ML pipeline using default parameter settings of scikit-learn library to build the model for each of the annotated datasets. The same preprocessing and same feature transformation technique for the text data have been performed using TF-IDF Vectorizer provided by scikit-learn library for default parameter settings.
We have trained three popular ML classifiers, e.g. Logistic Regression (LR), Support Vector Machine (SVM), and Random Forest (RF). For each of the three annotated datasets, we train the classifiers with the first {400, 500, 600, 700, 800} sets of paragraphs along with their corresponding labels respectively.
4.5 Model Evaluation
For all of the three annotated datasets for each training set of paragraphs, the same test set was used to evaluate the model. We have calculated the Macro F1 score as the accuracy parameter for comparing the cases.
5 Results and Discussions
We plotted the Macro F1 score with the number of paras we have used for training the model for each of the three annotated datasets. Fig. 4 will give us a fair comparison visualization.
For all three cases, the Macro F1 score increases as the number of para increases in the training set. The overall performance of DSEAL far exceeds the performances of Weak Supervision and Manual Annotation.
As we can compare, DSEAL utilizes techniques such as Active Learning, Strategic Sampling and Iterative Annotation which is not fully used in Weak Supervision or Manual Annotation [10,11]. Moreover, Rule based annotation which is applied in Weak Supervision is not done in DSEAL.
We computed the time required for each approach according to the number of paragraphs needed for annotation. In Manual Annotation and Weak Supervision, 4414 and 1376 paragraphs were annotated, taking roughly 66 hours and 12 minutes and 20 hours and 38 minutes, respectively. Meanwhile, DSEAL annotated 1137 paragraphs in just 17 hours. We also observe that DSEAL requires 600 paragraphs taking 9 hours to reach the benchmark accuracy which is obtained with 1300 paragraphs in 19 hours and 30 minutes as per our experiments.
6 Conclusion
In this paper we have proposed an efficient approach for strategic data annotations using divisive sampling and ensemble active learning. We have conducted experiments to comparatively analyze DSEAL with Weak Supervision and Manual Annotation. We find that the accuracy for DSEAL is 8.85% and 16.68% higher than Manual Annotation and Weak Supervision respectively. There is also a reduction in effort of 74.32% from Manual Annotation and 17.63% from Weak Supervision. The projected number also shows a reduction of 53.84% effort compared to the fully annotated data for achieving similar accuracy.
These results reveal that the DSEAL outperforms Weak Supervision and Manual Annotation significantly. In DSEAL, annotations happen for strategically selected paragraphs unlike Manual Annotation and Weak Supervision which results in better performance.
[2] Nithya Sambasivan et al. “Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes Al”. In: proceedings of the 2021 CHI Conference on Human Factors in Computing Systems. 2021, pp. 1-15.
[3] David Stodder and Why Data Preparation Matters. “Improving data preparation for business analytics”. In: Transforming Data With Intelligence 1.1 (2016), p. 41.
[4] url: link global-survey-the-state-of-ai-in-2020
[5] Pinar Donmez and Jaime G Carbonell. “Proactive learning: cost-sensitive active learning with multiple imperfect oracles”. In: Proceedings of the 17th ACM conference on Information and knowledge management. 2008, pp. 619-628.
[6] Google AI Platform Data Labeling Service pricing. url: https://cloud.google.com/ai-platform/data-labeling/pricing
[7] Weak Supervision: A New Programming Paradigm for Machine Learning. url: link
[8] A Tutorial on Active Learning. url: http://videolectures.net/ icml09_dasgupta_langford_actl/
[9] Dataset: CUAD. url: link atticus-open-contract-dataset-aok-beta
[10] Snorkel. url: https://snorkel.ai/
[11] Label Studio. url: https://labelstud.io/
[12] J. Zhang and Y. Yang, “Robustness of regularized linear classification methods text categorization,” in Proc. 26th Annu. Int. ACM SIGIR Conf. Res. Develop. Inf. Retr., Toronto, ON, Canada, Jul./Aug. 2003, pp. 190-197.
[13] D. Angluin and P. Laird, “Learning from noisy examples,” Mach. Learn., vol. 2, no. 4, pp. 343-370, 1988
We compare DataNeuron‘s Unsupervised learning algorithms to the most popular Language Models in benchmark experiments. This benchmarking is primarily intended to compare models capable of data annotation without any prior domain knowledge or pre-training (Zero-Shot).
Dataset
3 domain-specific datasets were used to compare the algorithms’ accuracy:
The most capable GPT-3.5 model, optimized for chat, at one-tenth the cost of the text-davinci-003. Supports up to 4,096 tokens with training data until September 2021.
We have picked this GPT version for the benchmarking since ChatGPT hosts the same model version, which is available to the general public.
Using pip install OpenAI, install the OpenAI library in your Python environment. After installation, create an OpenAI API key. Then use Openai.api_key = ‘key-extracted-from-openai’ to authenticate the API key.
2. ChatCompletion
Use the Chat Completion Class to call the “create” function, which serves as a model for sending requests and receiving API responses.
Please label each of the following 100 paragraphs strictly into one of these 6 classes: 1. sadness 2. anger 3. love 4. surprise 5. fear 6. joy. Separate answers with , for each of the paragraphs [“paragraph1”,”paragraph2”,………,”paragraph100”]
4. Benchmarking
Classification Report was generated by comparing the ground truth to the GPT 3.5 Output after creating classes on paragraphs with OpenAI libraries.
DataNeuron Platform (Stage 1)
Stage 1 models predict paragraphs based on the user-defined Masterlist/ Taxonomy. is equivalent to providing prompts or scope of the classification to the Zero-Shot LLMs. Stage 1 consists of proprietary Unsupervised models for annotation and DSEAL algorithms for strategic data sampling.
Result
Conclusion
DataNeuron Stage 1 performed better than pre-trained LLMs BERT BASE and ROBERTA across all the 3 datasets. Further it has comparable accuracies to BART LARGE for OSHUMED and CUAD datasets while outperforming it significantly on EMOTIONS dataset. DataNeuron Stage 1 models also outperformed GPT 3.5 in the benchmarking on CUAD and EMOTIONS dataset.
It is critical to note DataNeuron Stage 1 model was not given any sample paragraphs for pre-training, implying that Stage 1 models can automatically annotate with high accuracy without any prior domain knowledge.
Since DataNeuron models are light-weight it scales much better for the large data annotation workflows when compared to LLMs. At the same time DataNeuron is able to achieve comparable/ better accuracies with the proprietary Unsupervised models and DSEAL algorithms when compared to pre-trained LLMs at lesser cost/ time.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}