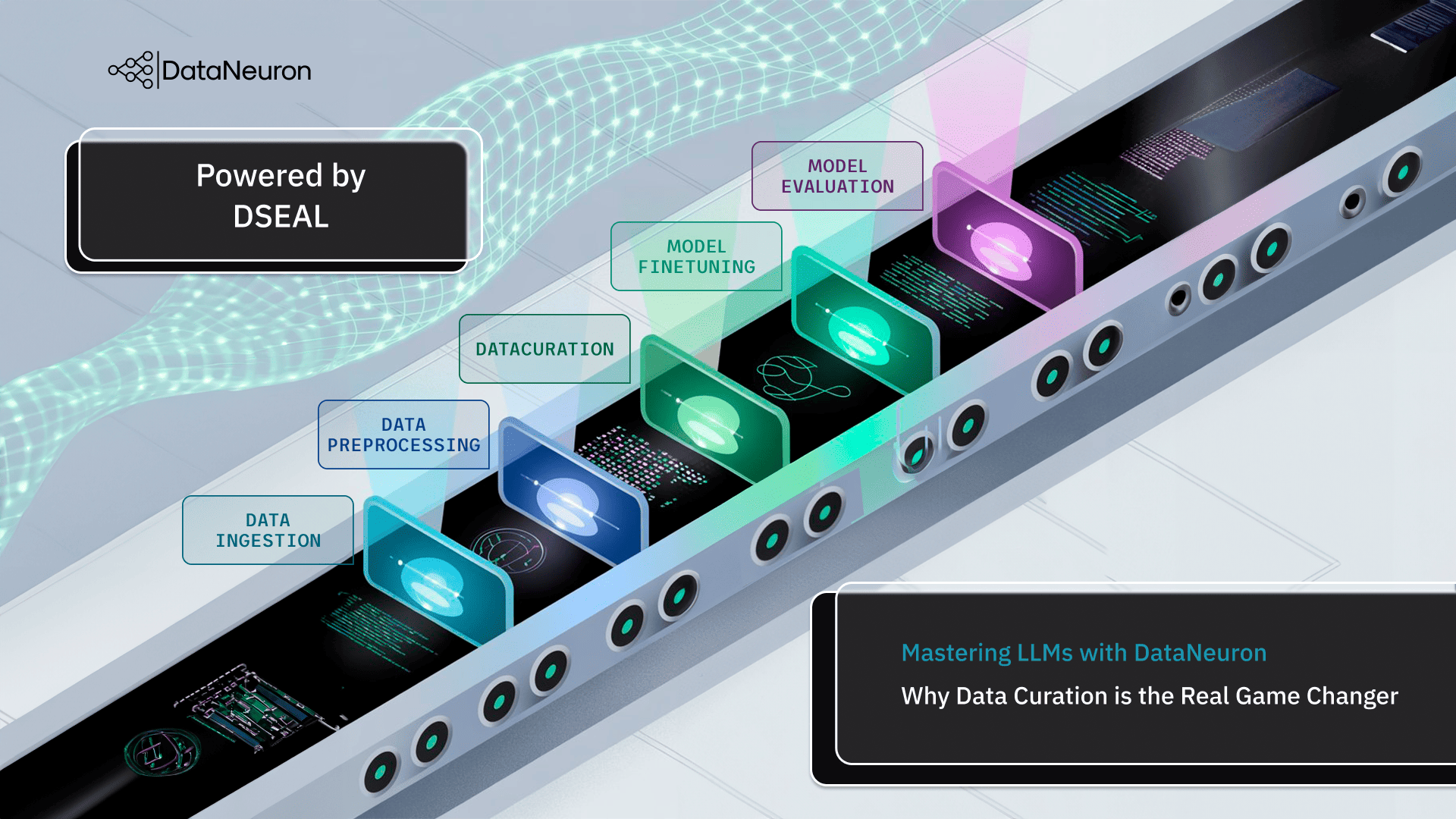
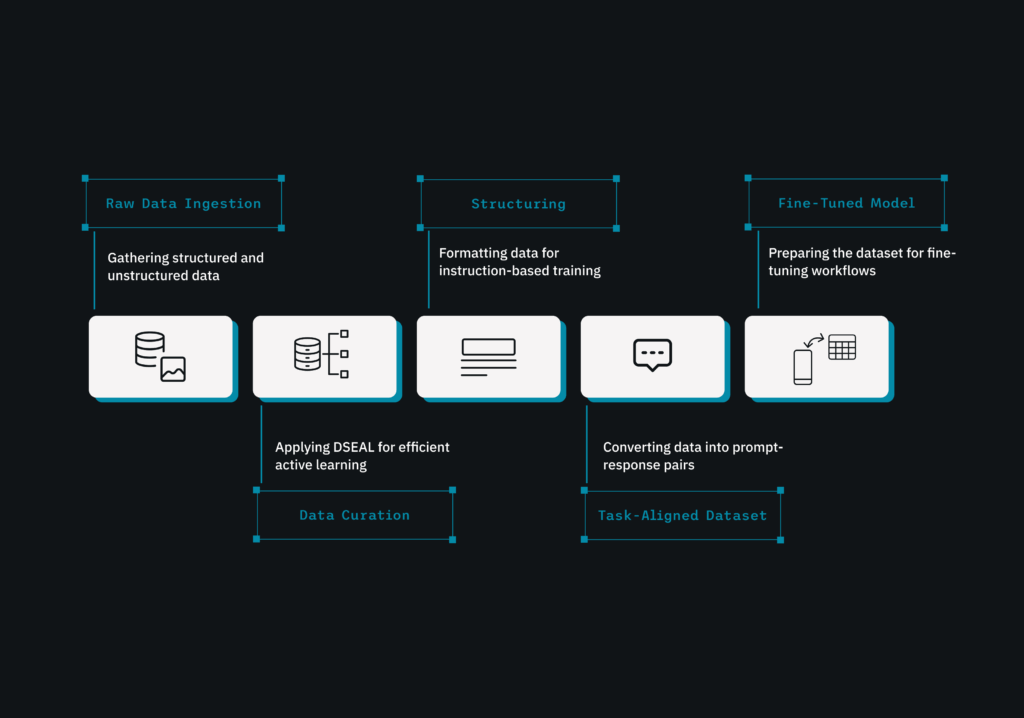
We’ve all seen how Large Language Models (LLMs) have revolutionized tasks, from answering emails and generating code to summarizing documents and navigating chatbots. In just one year, market growth increased from $3.92 billion to $5.03 billion in 2025, driven by the transformation of customer insights, predictive analytics, and intelligent automation.
However, not every AI challenge can(or should) be solved with a single, monolithic model. Some problems demand a laser-focused expert LLM, customized to your precise requirements. Others call for a team of specialised models working together like humans do.
At DataNeuron, we recognize this distinction in your business needs and empower enterprises with both advanced fine-tuning options and flexible multi-agent systems. Let’s understand how DataNeuron’s unique offerings set a new standard.
What is a Fine-Tuned LLM, Exactly?
Consider adopting a general-purpose AI model and training it to master a specific activity, such as answering healthcare queries, insurance questions, or drafting legal documents. That is fine-tuning. Fine-tuning creates a single-action specialist, an LLM that consistently delivers highly accurate, domain-aligned responses.
Publicly available models (such as GPT-4, Claude, and Gemini) are versatile but general-purpose. They are not trained using your confidential data. Fine-tuning is how you close the gap and turn generalist LLMs into private-domain experts.
With fine-tuning, you use private, valuable data to customize an LLM to your unique domain needs.
- Medical information (clinical notes, patient records, and diagnostic protocols is safely handled for HIPAA/GDPR compliance.
- Financial compliance documents
- Legal case libraries
- Manufacturing SOPs
Fine-Tuning Options Offered by DataNeuron
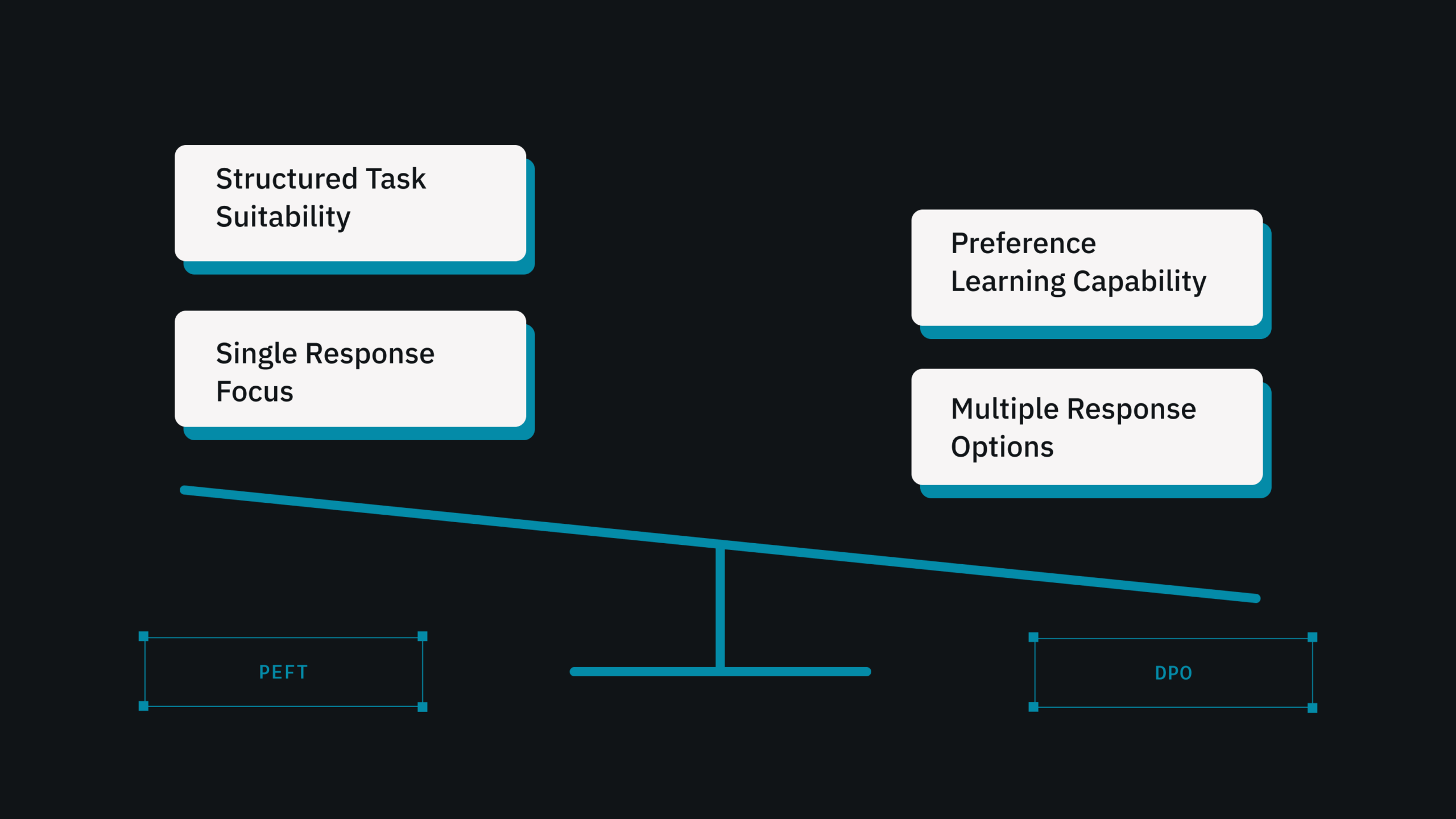
Parameter-Efficient Fine-Tuning: PEFT is a more efficient fine-tuning method that only changes a portion of the model’s parameters. PEFT (Prefix-Tuning for Efficient Adaptation of Pre-trained BERT) is a widely used approach with promising outcomes.
Direct Preference Optimization: DPO aligns models to human-like preferences and ranking behaviors. Ideal for picking multiple types of responses.
DataNeuron supports both PEFT and DPO workflows, providing scalable, enterprise-grade model customisation. These solutions enable enterprises to quickly adapt to new use cases without requiring complete model retraining.
If your work does not change substantially and the responses follow a predictable pattern, fine-tuning is probably your best option.
What is a Multi-Agent System?
Instead of one expert, you have a group of agents performing tasks in segments. One person is in charge of planning, another collects data, and another double-checks the answer. They work together to complete a task. That’s a multi-agent system, multiple LLMs (or tools) with different responsibilities that work together to handle complicated operations.
A multi-agent system involves multiple large language models (LLMs) or tools, each with distinct responsibilities, collaborating to execute complex tasks.
At DataNeuron, our technology is designed to allow both hierarchical and decentralized agent coordination. This implies that teams may create workflows in which agents take turns or operate simultaneously, depending on the requirements.
Agent Roles: Planner, Retriever, Executor, and Verifier
In a multi-agent system, individual agents are entities designed to perform specific tasks as needed. While the exact configuration of agents can be built on demand and vary depending on the complexity of the operation, some common and frequently deployed roles include:
Planner: Acts like a project manager, responsible for defining tasks and breaking down complex objectives into manageable steps.
Retriever: Functions as a knowledge scout, tasked with gathering necessary data from various sources such as internal APIs, live web data, or a Retrieval-Augmented Generation (RAG) layer.
Executor: Operates as the hands-on worker, executing actions on the data based on the Planner’s instructions and the information provided by the Retriever. This could involve creating, transforming, or otherwise manipulating data.
Verifier: Plays the role of a quality assurance specialist, ensuring the accuracy and validity of the Executor’s output by identifying discrepancies, validating findings, and raising concerns if issues are detected.
These roles represent a functional division of labor that enables multi-agent systems to handle intricate tasks through coordinated effort. The flexibility of such systems allows for the instantiation of these or other specialized agents as the specific demands of a task dictate.

Key Features:
- Agents may call each other, trigger APIs, or access knowledge bases.
- They could be specialists (like a search agent) or generalists.
- Inspired by how individuals delegated and collaborated in teams.
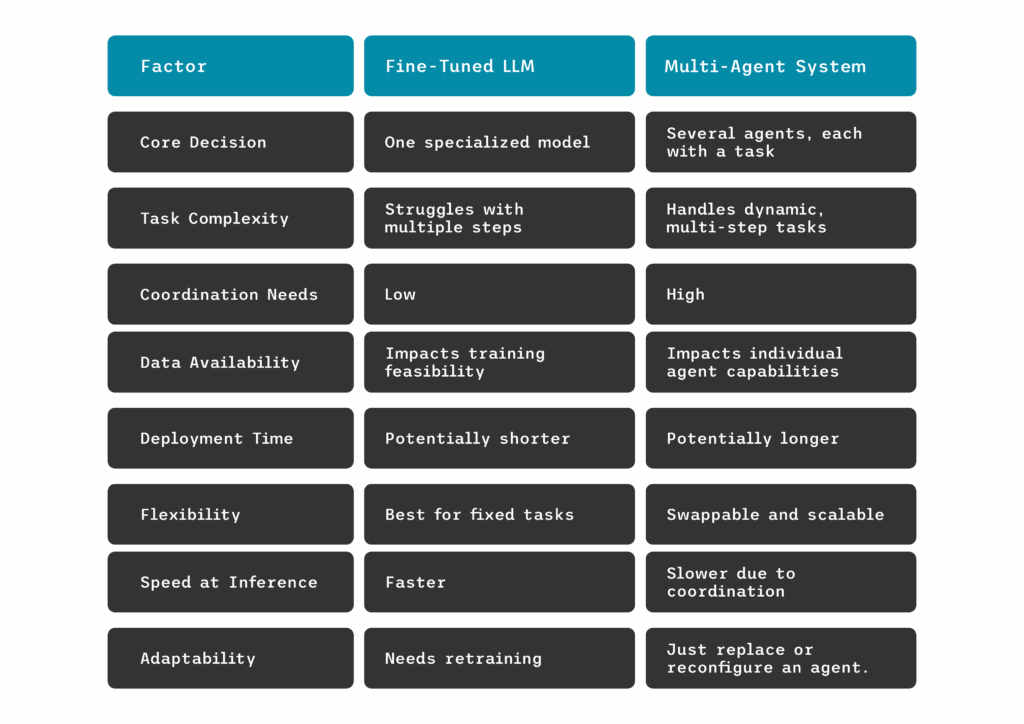
Choosing Between Fine-Tuned LLMs and Multi-Agent Systems: What Points to Consider
Data In-Hand
If you have access to clean, labeled, domain-specific data, a fine-tuned LLM can generate high precision. These models thrive on well-curated datasets and learn only what you teach them.
Multi-agent systems are better suited to data that is dispersed, constantly changing, or unstructured for typical fine-tuning. Agents such as retrievers may extract essential information from APIs, databases, or documents in real time, eliminating the need for dataset maintenance.
Task Complexity
Consider task complexity as the number of stages or moving pieces involved. Fine-tuned LLMs are best suited for targeted, repeated activities. You teach them once, and they continuously perform in that domain.
However, when a job requires numerous phases, such as planning, retrieving data, checking outcomes, and initiating actions, a multi-agent method is frequently more suited. Different agents specialize and work together to manage the workflow from start to finish.
Need for Coordination
Fine-tuned models may be quite effective for simple reasoning, especially when the prompts are well-designed. They can use what they learnt in training to infer, summarize, or produce.
However, multi-agent systems excel when the task necessitates more back-and-forth reasoning or layered decision-making. Before the final product goes into production, a planner agent breaks down the task, a retriever recovers information, and a validator verifies for accuracy.
Time to Deploy
Time is typically the biggest constraint. Fine-tuning needs some initial investment: preparing data, training the model, and validating results. It’s worth it if you know the assignment will not change frequently.
Multi-agent systems provide greater versatility. You can assemble agents from existing components to get something useful up and running quickly. Need to make a change? Simply exchange or modify an agent; no retraining is required.
Use Cases: Fine-Tune Vs. Multi-Agent
The best way to grasp a complicated decision is through a few tangible stories. So here are some real-world scenarios that make the difference between fine-tuned LLMs and multi-agent systems as clear as day.
Scenario 1: Customer Support Chatbot
Company: HealthTech Startup
Goal: Develop a chatbot that responds to patient queries regarding their platform.
Approach: Fine-Tuned LLM
They trained the model on:
- Historical support tickets
- Internal product documentation
- HIPAA-compliant response templates
Why it works: The chatbot provides responses that read on-brand, maintain compliance rules, and do not hallucinate because the model was trained in the company’s precise tone and content.
Scenario 2: Market Research Automation
Business: Online Brand
Objective: Be ahead of the curve by automating product discovery.
Approach: Multi-Agent System
The framework includes:
- Search Agent to crawl social media for topically relevant items
- Sentiment and Pattern Recognition Analyzer Agent
- Strategic Agent to advise on product launch angles
Why it works: The system constantly monitors the marketplace, learns to adjust to evolving trends, and gives actionable insights that are free from human micromanagement.
At DataNeuron, we built our platform to integrate fine-tuned intelligence with multi-agent collaboration. Here’s what it looks like: Various agents, both pre-built and customizable, can be used for NLP tasks like NER, document search, and RAG. Built-in agents offer convenience for common tasks, while customizable agents provide flexibility for complex scenarios by allowing fine-tuning with specific data and logic. The choice depends on task complexity, data availability, performance needs, and resources. Simple tasks may suit built-in agents, whereas nuanced tasks in specialized domains often benefit from customizable agents. Advanced RAG applications frequently necessitate customizable agents for effective information retrieval and integration from diverse sources.
So, whether your activity is mundane or dynamically developing, you get the ideal blend of speed, scalability, and intelligence. You don’t have to pick sides. Instead, choose what best suits your business today. We are driving this hybrid future by making it simple to design AI that fits your workflow, not the other way around.