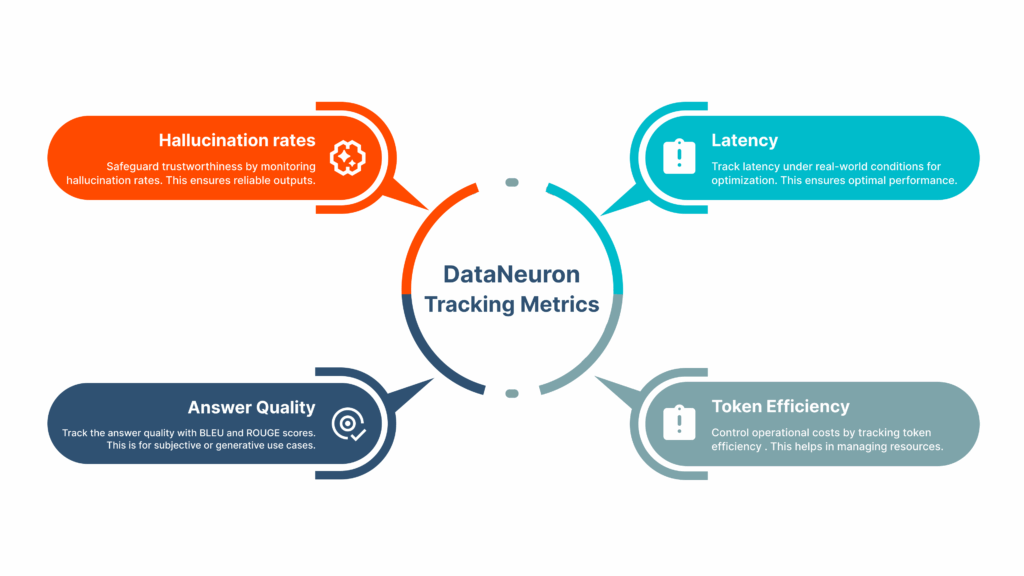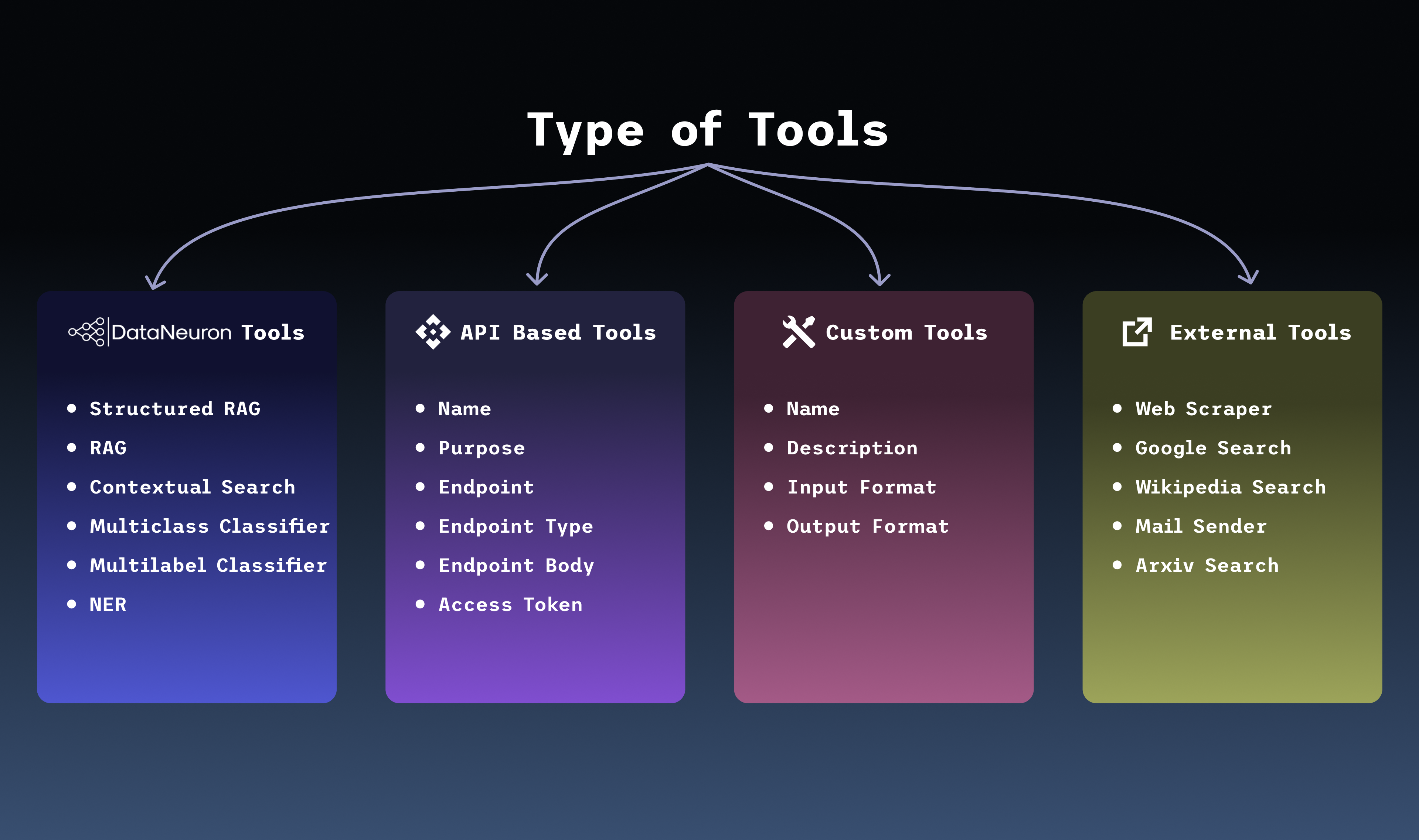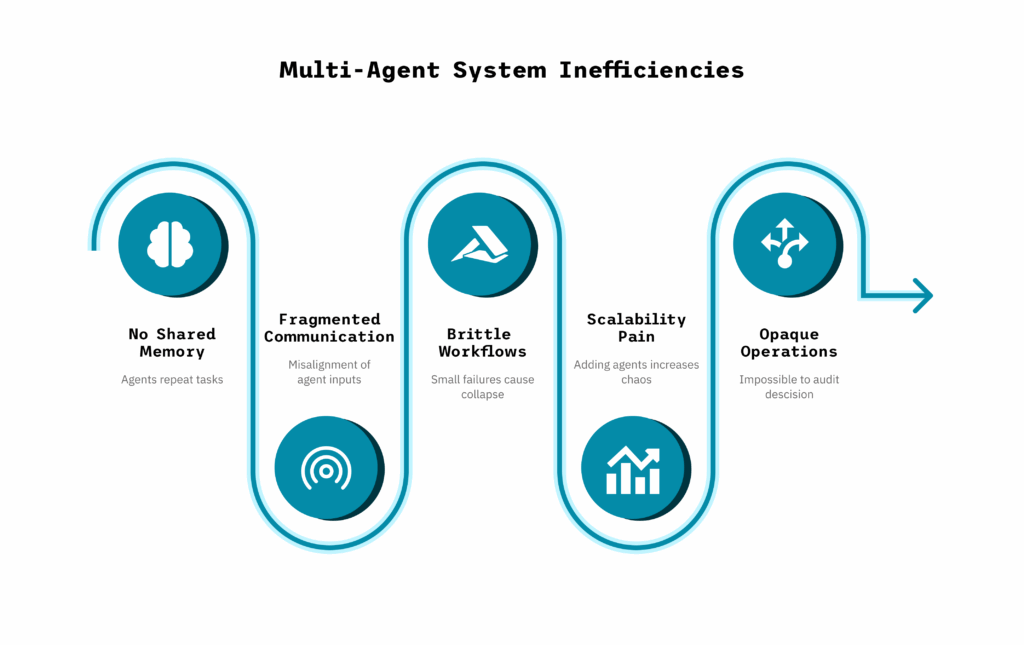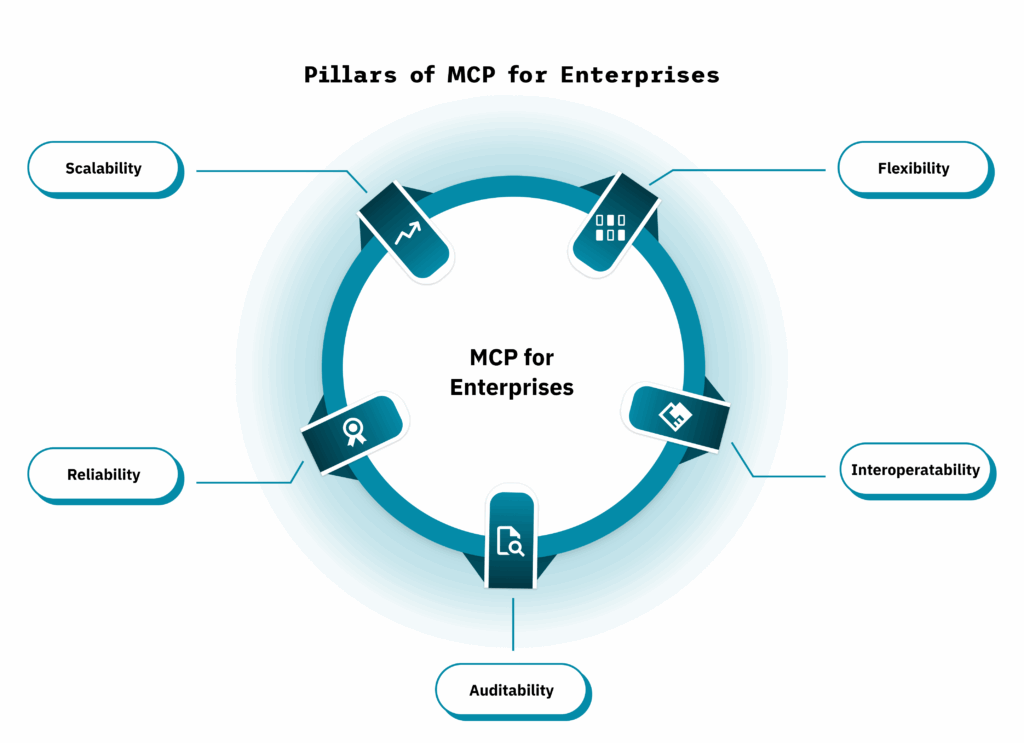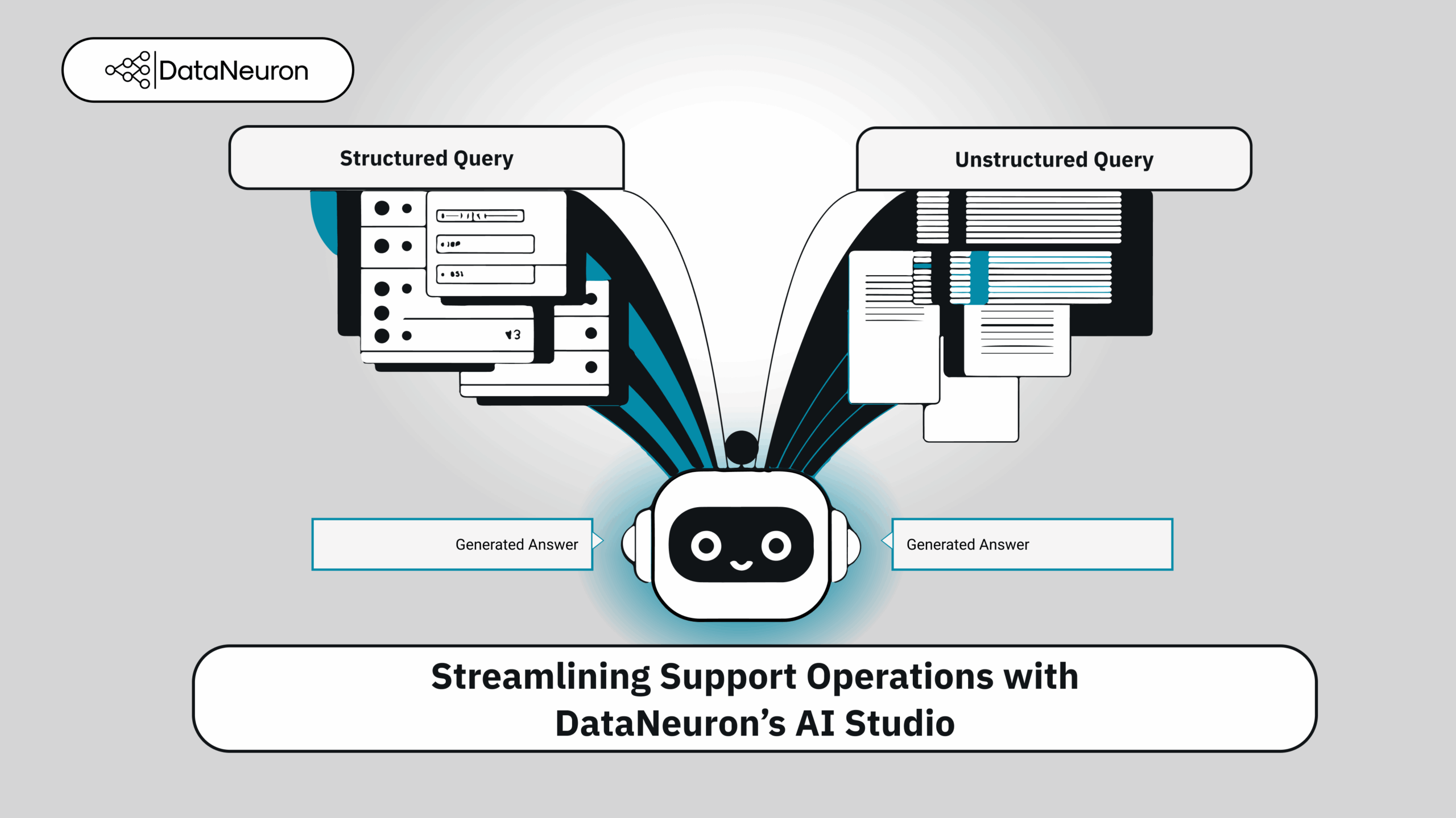
AI-integrated systems once thrived in silos: text models parsed documents, vision models recognized images, and models detected sounds. Yet people rarely process information in isolation. We read captions under pictures, watch videos with sound, and naturally link meaning across channels.
Multimodal embeddings bring this human-like perception to AI, creating a unified approach to understanding and relating text and images. At DataNeuron, we’re evolving our Retrieval-Augmented Generation (RAG) framework from text-only to a truly multimodal experience, enabling more context-aware insights across diverse data types.
From Single-Modality to Multimodal Intelligence
Traditional machine learning pipelines were siloed by modality:
- Natural Language Processing (NLP) for text
- Computer Vision (CV) for images
Each used its own features, architectures, and training data. That’s why a text embedding could not directly relate to an image feature. However, real-world tasks need cross-modal understanding.
A self-driving car combines camera feeds with sensor text logs. An e-commerce engine pairs product descriptions with photos. A customer support bot must interpret text, as well as screenshots or voice messages. Without a common representation, these systems can’t easily search, rank, or reason across mixed inputs.
What Are Multimodal Embeddings?
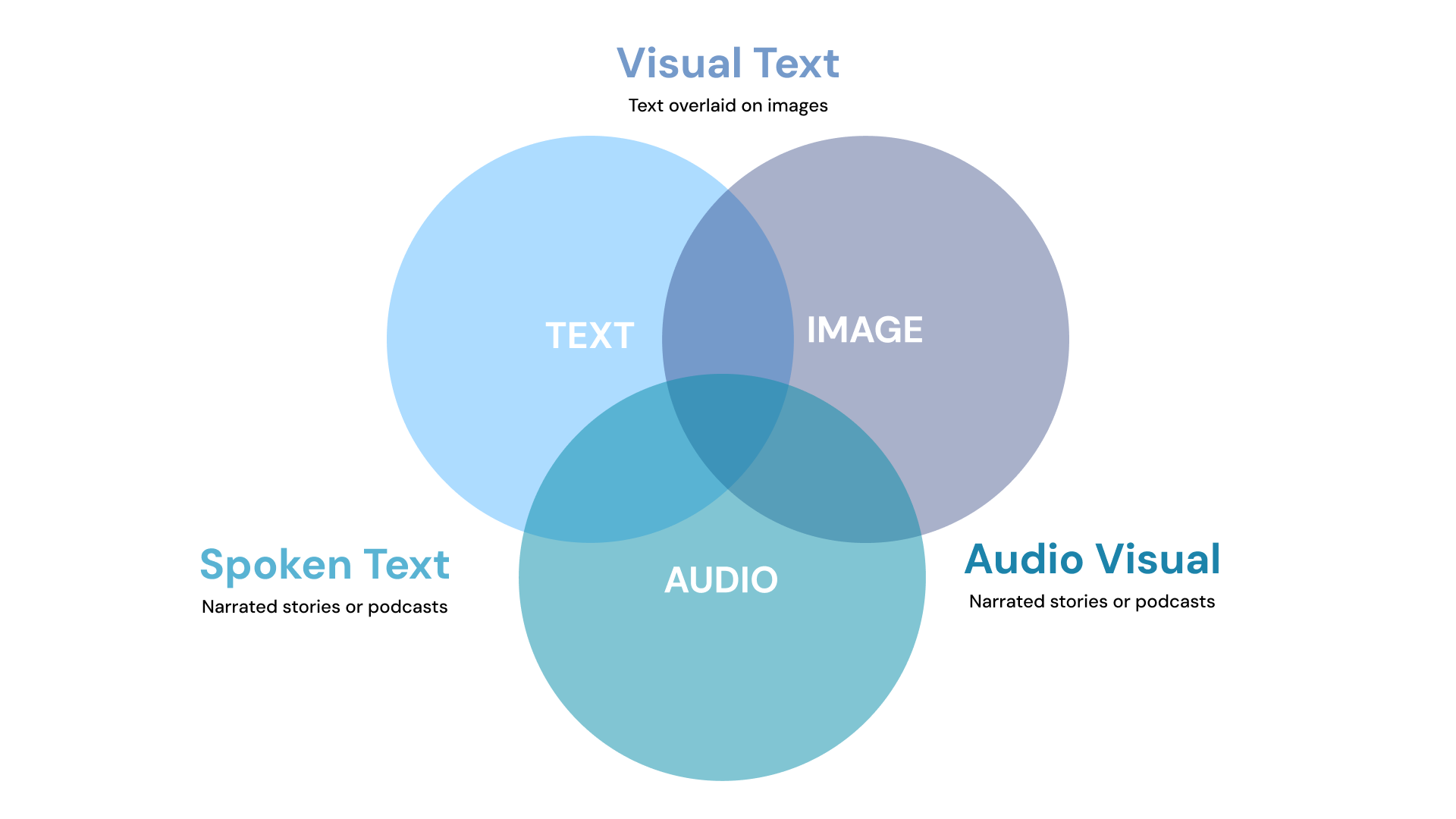
An embedding is simply a vector (a list of numbers) that encodes the meaning of data.
- In text, embeddings map semantically similar words or sentences near each other in vector space.
- In images, embeddings map visually similar content near each other.
Multimodal embeddings go further… they map different modalities into a shared vector space. This means the caption “a red sports car” and an actual photo of a red sports car end up close together in that space.
How Do Multimodal Embeddings Work?
There are two main approaches, both relevant to DataNeuron’s roadmap.
1. Convert Non-Text Modalities into Text First
Here, each modality is preprocessed into text-like tokens:
- Images → captions or alt-text via a vision model
Once everything is in text, we can use a text embedding model (e.g., OpenAI, Cohere, or open-source models) to generate vectors. DataNeuron currently offers this method by default: you upload mixed data, our system normalizes it to text, and we build a unified vector store for retrieval.
2. Direct Multimodal Embedding Models
Alternatively, we can train or use models that natively embed text or images into the same space without converting them. DataNeuron is experimenting with this second route, where we integrate open-source and licensed (paid) embeddings to give our users both options.
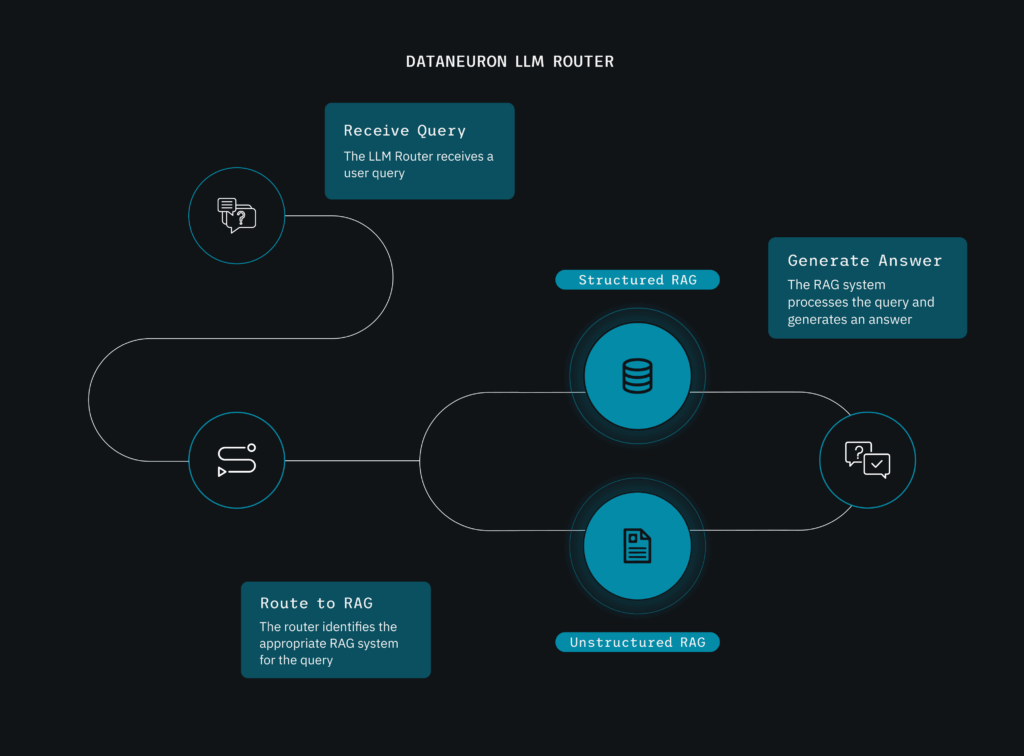
Why Multimodal Embeddings Matter for RAG
Retrieval-Augmented Generation (RAG) traditionally enhances LLMs by retrieving text chunks relevant to a query. But enterprise data rarely lives as plain text. You may have:
- PDFs with embedded images
- Sensor logs with metadata
By extending RAG into multimodal territory, DataNeuron enables users to:
- Search across formats (“Find me slides, videos mentioning Product X”)
- Contextualize outputs (“Generate a summary of this image plus its caption”)
Reduce preprocessing overhead (no manual transcription or tagging needed)
Humans naturally combine multiple senses to understand context. Multimodal embeddings give machines a similar capability, mapping text, images, and sounds into a shared meaning space.
For DataNeuron, adding multimodal embeddings on top of our RAG stack means customers no longer need to flatten their data into text. Instead, they can bring their data as-is and still get unified, context-aware retrieval and generation. This democratizes multimodal AI for enterprises that can’t afford to train such models themselves. We’re curating and integrating the best open and commercial models to give our users immediate and practical power.
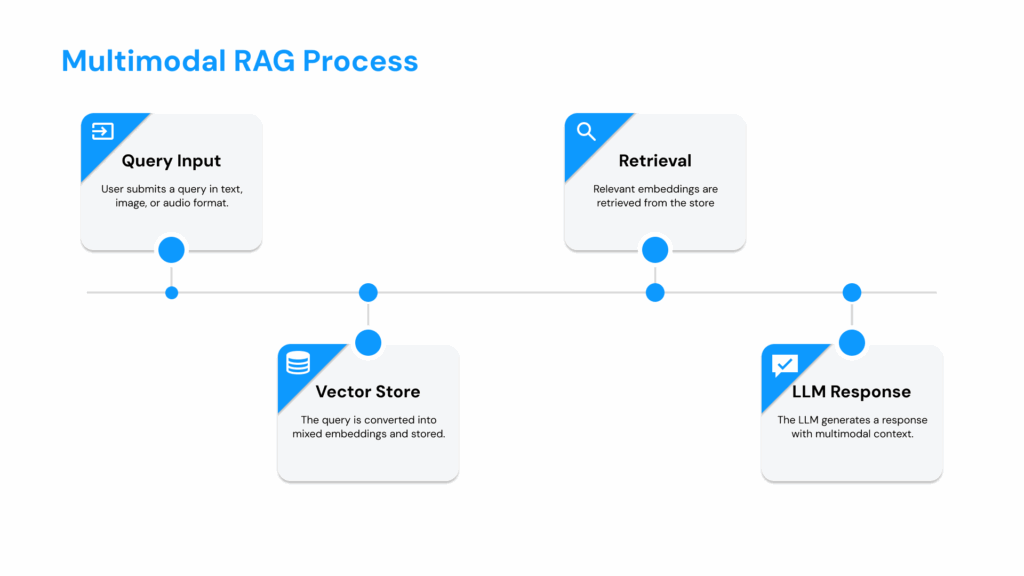
DataNeuron’s Multimodal Embedding Strategy
We’ve structured our approach around three pillars:
Unified User Experience
Users can upload or stream text, images, or audio. Our system either converts non-text into text first or applies a multimodal embedding model directly. The resulting vectors live in a single store, so cross-modal queries “just work.”
Choice of Embedding Models
We support both open-source and paid/licensed embeddings. This lets customers start with free models for experimentation, then switch to higher-accuracy or enterprise-grade embeddings without rewriting pipelines. Some examples of embedding models supported by DataNeuron include open-source: CLIP, AudioCLIP, OpenCLIP; paid APIs: commercial text + image embeddings from major providers.
Future-Ready Architecture
Our vector store and RAG engine are designed to handle not only text, image, and audio today, but also include richer modalities like video and sensor data tomorrow. We’re treating “embedding as a service” as a core building block of DataNeuron.

Humans naturally combine multiple senses to understand context. Multimodal embeddings give machines a similar capability, mapping text, images, and sounds into a shared meaning space, unlocking better search, smarter generation, and more intuitive user experiences.
At DataNeuron, we’re extending our platform from text-centric RAG to truly multimodal RAG. By supporting both “convert to text first” and “direct multimodal embedding” approaches, in addition to offering open-source and paid models, we provide customers with flexibility and scalability.