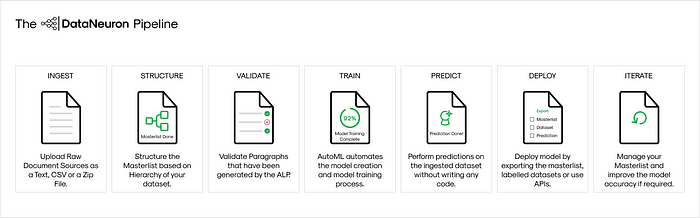
The DataNeuron Pipeline
DataNeuron helps you accelerate and automate human-in-loop annotation for developing AI solutions. Powered by a data-centric platform, we automate data labeling, the creation of models, and end-to-end lifecycle management of ML.
Ingest
Upload Visualization
Users can upload the entire data available with them without performing any filteration to remove out of scope paragraphs.
The data can be uploaded in various file formats supported by the platform.
The platform has an in-built feature that can handle out-of-scope paragraphs and separate them from the classification data. This functionality is optional and can be toggled on or off anytime during the process.
Structure
Structure Visualization
The next step is the creation of the project structure.
Instead of a simple flat structure with just the classes defined, we provide the user with the option to create a multi-level (hierarchical) structure so that he can extract the data grouped into domains, subdomains, and indefinitely continue dividing into further subparts depending on his needs.
Any of the defined nodes can be marked as a class for the data to be classified into irrespective of the level on which it is in the hierarchy. This provides flexibility to create any level of ontology for classification.
Validate
Validate Visualization
User does not have to go through the entire dataset to sort out paragraphs that belong to a certain class and label them to provide training data for the model, which can be a tedious and difficult task.
We propose a validation based approach:
- The platform provides the users with suggestions of paragraphs that are most likely to belong to a certain category/class based on an efficient context-based filtering criterion.
- The user simply has to validate the suggestions, i.e, check whether or not the suggested class is correct.
This reduces the effort put in by the user in filtering out the paragraphs belonging to a category from the entire dataset by a large margin.
The strategic annotation technique allows the user to adopt a ‘one-vs-all’ strategy, which makes the task far easier than having to take into consideration all the defined classes, which can be a large number depending on the problem at hand, while tagging a paragraph.
Our intelligent filtering algorithm ensures “edge-case” paragraphs, i.e paragraphs that do not have obvious correlation with a class but still belong to that class, are not left out.
This step is broken down into 2 stages:
- The validation done by the user in the first stage is used for determining the annotation suggestions offered in the second stage.
- Each batch of annotation is used to improve the accuracy of the filtering algorithm for the next batch.
The platform also provide a summary screen after each batch of validation which provides the user with an idea as to many more paragraphs he might need to validate per class in order to achieve a higher accuracy.
It also helps determine when to stop the validation for a specific class and focus more on a class for which the platform projects low confidence.
Train
Train Visualization
User invests virtually no effort into the model training step and the model training can be initiated with the simple click of a button.
The complete training process is automatic which performs preprocessing, feature engineering, model selection, model training, optimization and k-fold validation.
After the final model is trained, the platform shows a detailed report of the trained model is presented to the user which includes the overall accuracy of the model as well as the accuracy achieved per class.
Iterate
Iterate Visualisation
Once the model has been trained, we provide the user with 2 options:
- Continue to the deployment stage if the trained model matches their expectations.
- If the model does not achieve the desired results, the user can choose to go back and provide more training paragraphs (by validating more paragraphs or uploading seed paragraphs) or alter the project structure to remove some classes and then retrain the model to achieve better results.
Deploy (“No-Code” Prediction Service)
Deploy Visualisation
Apart from providing the final annotations on the data uploaded by the user using the trained model, we also provide a prediction service which can be used to make a prediction on any new paragraphs in exchange for a very minimal fee.
This does not require any knowledge of coding and users can utilize this service for any input data from the platform.
This can also be integrated into other platforms by making use of the exposed prediction API or the deployed Python package.
No Requirement for a Data Science/Machine Learning Expert
The DataNeuron ALP is designed in such a way that no prerequisite knowledge of data science or machine learning is required to utilize the platform to its maximum potential.
For some very specific use cases, a Subject Matter Expert might be required but for the majority of use cases, an SME is not required in the DataNeuron Pipeline.
Leave a Reply