A leading D2C business in India and international markets, renowned for its home and sleep products, aimed to enhance customer support. As a major retailer of furniture, mattresses, and home furnishings, they faced a major challenge: inefficiency in handling a high volume of diverse customer inquiries about product details, order status, and policies, resulting in slow response times and customer frustration. The company required a solution capable of understanding and responding to definitive customer queries, an area where existing chatbot solutions had fallen short.
The DataNeuron Solution: Smart Query Handling with LLM Studio
To solve this, the team implemented a smart, hybrid retrieval solution using DataNeuron’s LLM Studio, built to understand and respond to diverse customer queries, regardless of how or where the data was stored.
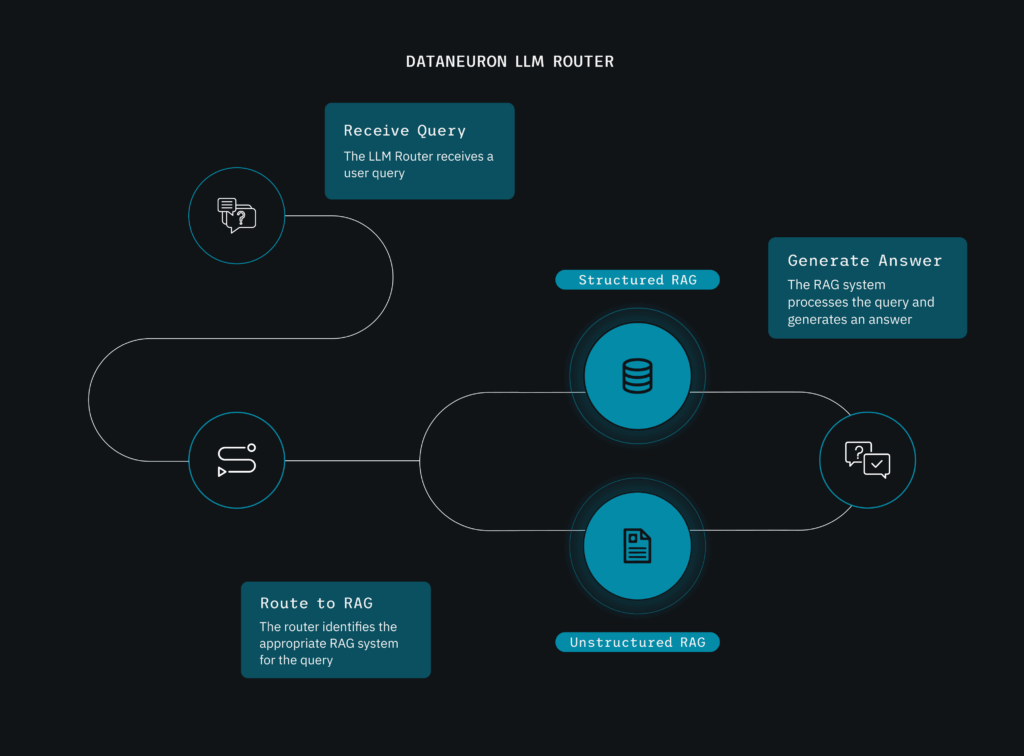
Step 1: Intelligent Classification with the LLM Router
The first stage was a classifier-based router that automatically determined whether a query required structured or unstructured information. For example:
- Structured: “What is the price of a king-size bed?”
- Unstructured: “What is the return policy if the product is damaged?”
The router leveraged a wide set of example queries and domain-specific patterns to route incoming questions to the right processing pipeline.
Step 2: Dual-Pipeline Retrieval Augmented Generation (RAG)
Once classified, queries flowed into one of two specialized pipelines:
Structured Query Pipeline: Direct Retrieval from Product Databases
Structured queries were translated into SQL and executed directly on product databases to retrieve precise product details, pricing, availability, etc. This approach ensured fast, accurate answers to data-specific questions.
Unstructured Query Pipeline: Semantic Search + LLM Answering
Unstructured queries were handled via semantic vector search powered by DataNeuron’s RAG framework. Here’s how:
- The question was converted into a vector embedding.
- This vector was matched with the most relevant documents in the company’s vector database (e.g., policy documents, manuals).
- The matched content was passed to a custom LLM to generate grounded, context-aware responses.
Studio Benefits: Customization, Evaluation, and Fallbacks
The LLMs used in both pipelines were customized via LLM Studio, which offered:
Fallback mechanisms when classification confidence was low, such as routing queries to a human agent or invoking a hybrid LLM fallback.
Tagging and annotation tools to refine training data.
Built-in evaluation metrics to monitor performance.
DataNeuron’s LLM Router, transformed our support: SQL‑powered answers for product specs and semantic search for policies now resolve 70% of tickets instantly, cutting escalations and driving our CSAT, all deployed in under two weeks.
– Customer Testimony
The DataNeuron Edge
DataNeuron LLM Studio automates model tuning with:
- Built-in tools specifically for labeling and tagging datasets.
- LLM evaluations to compare performance before and after tweaking.
Substantive changes introduced:
- Specifically stated “service” and “cancellation” to address comments.
- Highlighted the “Router capability dataset with lots of questions” to highlight the importance of data diversity for the classifier.
- Detailed the process of the “Structure RAG” pipeline, including natural language to SQL and back to natural language.
Leave a Reply