The adoption of Large Language Models (LLMs) has transformed how industries function, unlocking capabilities from customer support automation to improving human-computer interactions. Their adoption is soaring, with MarketsandMarkets projecting the global LLM market to grow at a compound annual growth rate (CAGR) of over 35% in the next five years. Yet, many businesses that rush to adopt these models are discovering a critical insight: the model itself isn’t what sets you apart your data does.
While impressive, pre-trained LLMs are fundamentally generalists. They are trained on a broad, diverse pool of public data, making them strong in language understanding but weak in context relevance. A well-curated dataset ensures that an LLM understands industry jargon, complies with regulatory constraints, and aligns with the client’s vision.
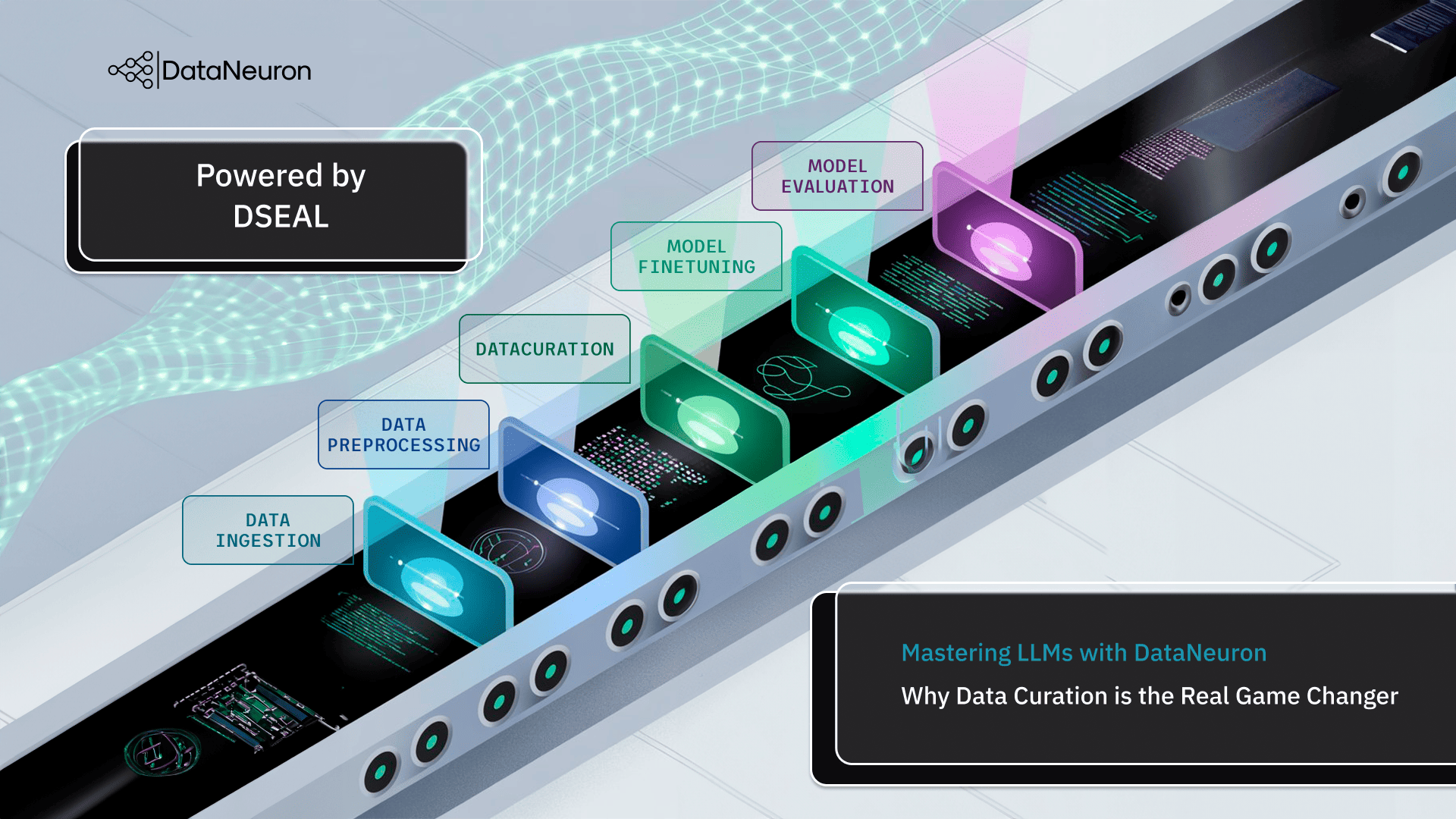
At DataNeuron, we’ve built our approach around this idea. Our Divisive Sampling for Efficient Active Learning (DSEAL) framework redefines what it means to prepare data for fine-tuning. Rather than throwing thousands of generic examples at a model, DSEAL enables the creation of focused, instructive, and diverse datasets while maintaining speed and confidentiality with minimal manual intervention.
Why Data Curation is the Hidden Engine Behind Fine-Tuning
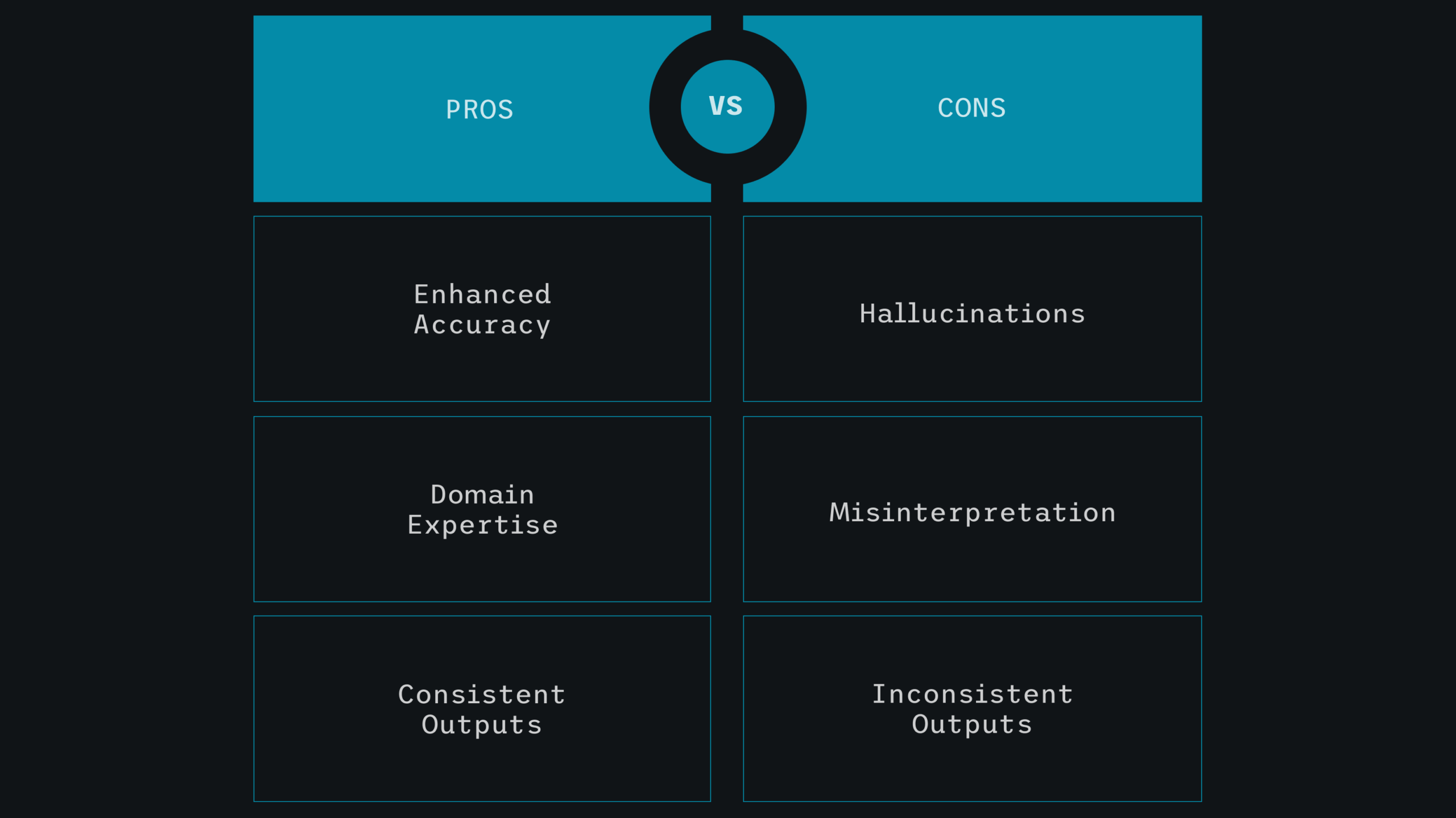
You wouldn’t train a legal assistant with engineering textbooks. Yet many enterprises expect LLMs trained on internet data to perform highly specialized tasks with minimal adaptation. This mismatch leads to a familiar set of issues: hallucination, shallow reasoning, and a lack of domain fluency.
The data that the model has or hasn’t seen contributes to these challenges. Fine-tuning a model with domain-specific examples allows it to grasp the nuances of your vocabulary, user expectations, and compliance norms. Nonetheless, fine-tuning is sometimes misinterpreted as a process concentrated on coding.
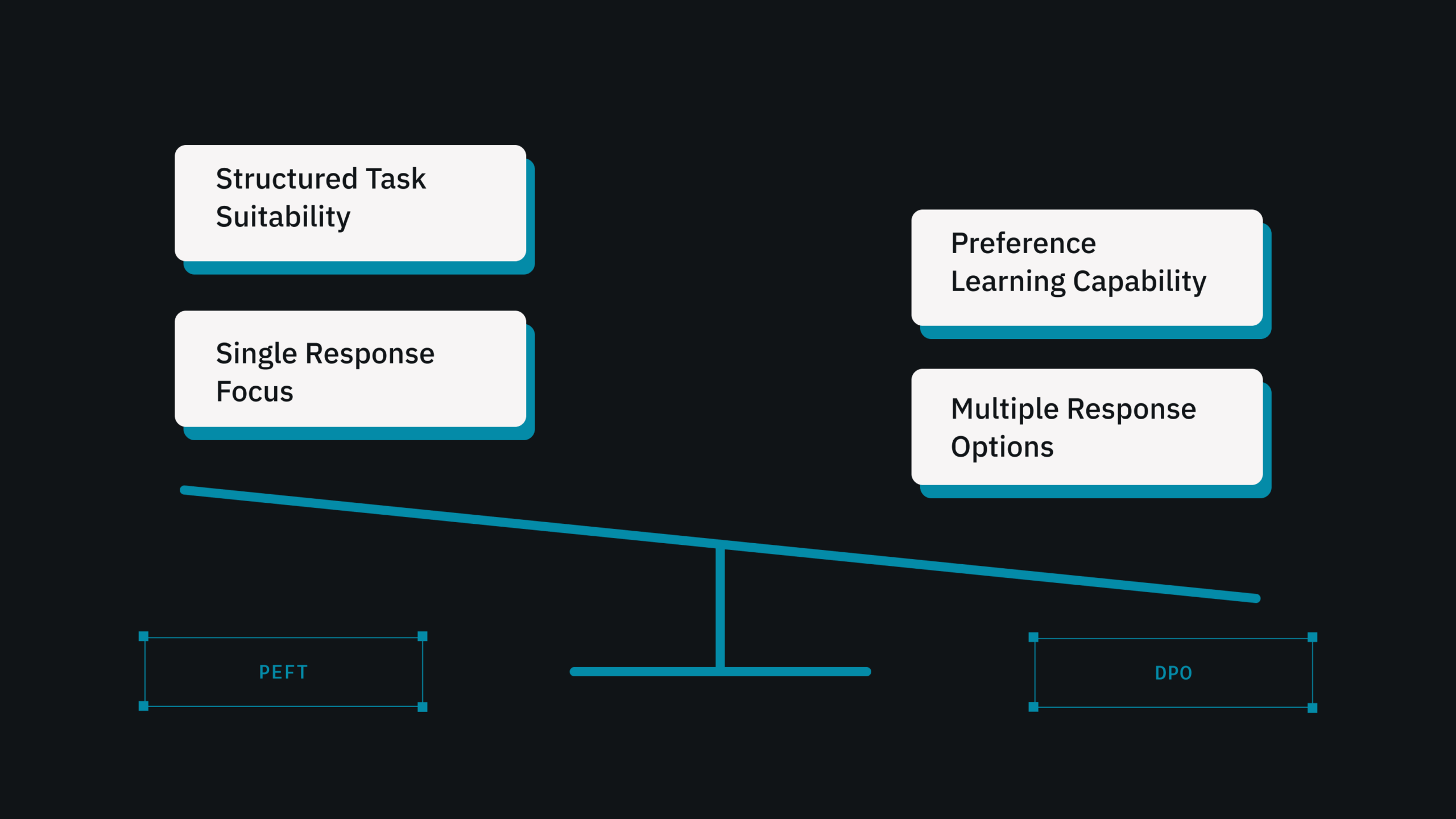
In practice, 80% of successful LLM fine-tuning depends on one factor: the correct data. We provide two fine-tuning options: PEFT and DPO, both of which are fully dependent on the quality of the incoming dataset.
Without sufficient curation, fine-tuning can provide biased, noisy, or irrelevant results. For instance, a financial LLM trained on poorly labeled transaction data may misidentify fraud tendencies. A healthcare model analyzing unstructured clinical notes may make harmful recommendations.
LLM Customization Starts with Curation, Not Code
Enterprises often approach LLM customization like a software engineering project: code first, optimize later. But with LLMs, data>code is where the transformation begins. Fine-tuning doesn’t start with scripts or API’s, it begins with surfacing the right example from your data sources.
Whether you employ open-source models or integrate with closed APIs, the uniqueness of the dataset makes our platform an ideal place to collaborate. Your support tickets, policy documents, email logs, and chat exchanges include an array of concealed data. However, they are distorted, inconsistent, and unstructured.
Curation turns this raw material into clarity. It is the process of identifying relevant instances, clearing up discrepancies, and aligning them with task requirements. At scale, it enables LLMs to progress from knowing a lot to understanding what matters.
This is why our clients don’t start their AI journey by deciding whether to use GPT or Llama; they begin by curating a dataset that reflects the tasks they care about. With the correct dataset, any model can be trained into a domain expert.
DataNeuron’s platform automates 95% of dataset creation, allowing businesses to prioritize strategic sampling and validation over human labeling. And the output? DataNeuron’s prediction API enables faster deployment, improved accuracy, and smoother integration.
Why Scaling Data Curation is Challenging Yet Important
For most companies, data curation is a bottleneck. It’s easy to underestimate how labor-intensive this procedure may be. Manually reviewing text samples, labeling for context, and ensuring consistency is an inefficient procedure that cannot be scaled.
We focus on quality over volume. Models trained using irrelevant or badly labeled samples frequently perform worse than models that were not fine-tuned at all. Add to this the complexities of data privacy, where sensitive internal documents cannot be shared with external tools, and most businesses find themselves trapped.
This is where we invented the DSEAL framework, which revolutionized the equation.
How DataNeuron’s DSEAL Framework Makes High-Quality Curation Possible
DSEAL is our solution to the most common problems in AI data preparation. DSEAL solves a basic issue in machine learning: the inefficiency and domain limitation of classic active learning methods. It’s a system designed to automate what’s slow, eliminate what’s unnecessary, and highlight the things that matter.
What makes DSEAL different from others?
- 95% Curation Automation: From ingestion to labeling, the system does the majority of the labor.
- Task-aligned sampling: DSEAL strategically samples across edge cases, structures, and language trends rather than random examples.
- Instruction-First Formatting: The curated data is organized to match instruction-tuned models, increasing relevance and accuracy.
- Private by Design: All processes run inside the enterprise environment; no data leaves your perimeter.
The change from brute-force annotation to smart, minimum, domain-adaptive sampling distinguishes DSEAL in today’s noisy and model-saturated market.
Key Takeaways
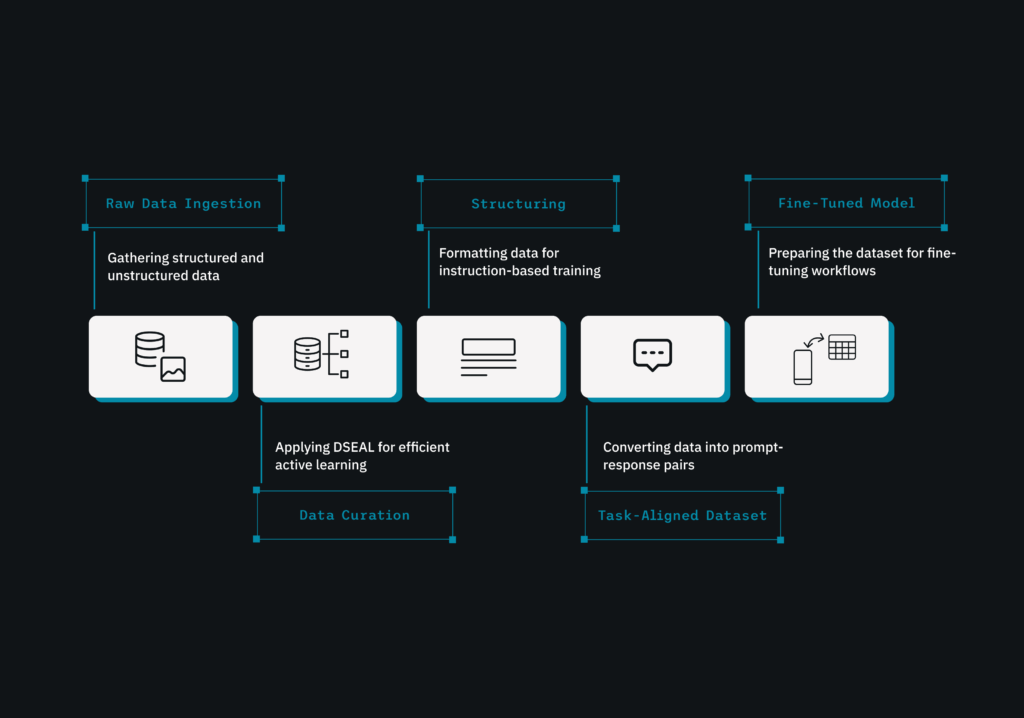
From raw to model-ready in four steps:
- Raw Data Ingestion: Whether it’s email threads or chat logs, the data enters the system untouched.
- Cleaning and Structuring: We remove duplicates, normalize formats, and extract only the content that is relevant to your aims.
- Instruction formatting: It involves converting data into prompt-response pairs or structuring it for preference-based training.
- Model-Ready Dataset: The completed dataset is ready for fine-tuning procedures, complete with traceability and metrics.
Fine-tuning is no longer about model design but about context and detail. Your business already has everything it needs to create world-class AI: its data. The difficulty lies in converting the data into a structured, informative resource from which an LLM may learn.
With DSEAL, DataNeuron turns curation from a manual bottleneck to a strategic advantage. We help you go from data chaos to clarity, providing your models the depth and focus they require to operate in the real world.
Leave a Reply